
近日,一项来自Sapient Intelligence的研究再次引爆AI领域。由00后清华校友王冠主导开发的2700万参数小模型HRM(Hierarchical Reasoning Model),在多个推理任务中超越了当前主流的大型模型,包括o3-mini-high和DeepSeek-R1。令人惊讶的是,这一模型并未依赖传统的思维链机制,仅用1000个训练样本便展现出卓越的推理能力。
这项研究不仅挑战了Transformer架构的统治地位,也再次引发了关于“小模型能否实现大智能”的讨论。HRM的成功在于其仿脑的双层循环模块设计,模拟大脑的分层处理机制与多时间尺度运作,从而实现了高效的推理与规划能力。
HRM的核心技术主要包括五大创新点。首先,它引入了分层循环模块和时间尺度分离机制。高层模块负责抽象规划,低层模块执行细节计算,两者协同工作,避免了传统模型在深度增加时出现的性能瓶颈。
其次,该模型采用了分层收敛机制。通过高阶模块更新引导低阶模块进入新的收敛周期,有效避免了过早收敛问题,使模型在处理复杂任务时更具持续性与灵活性。
第三,HRM引入了近似梯度技术,大幅降低了训练时的内存需求。不同于传统模型需要保存所有中间状态,HRM仅根据最终结果进行梯度反推,更加贴近生物大脑的学习方式。
第四项创新是深度监督机制。模型在训练过程中被划分为多个阶段,每个阶段结束后进行评估和调整,提升学习效率,类似学生阶段性考试的方式。
最后,自适应计算时间机制使HRM能够根据不同任务的复杂度动态调整推理时间。简单任务快速响应,复杂任务则投入更多计算资源,从而在效率与准确性之间取得平衡。
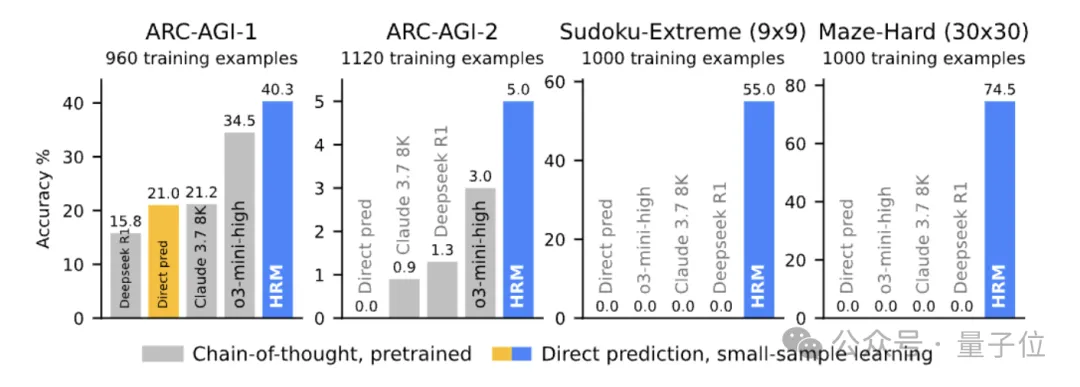
在多项测试中,HRM表现出色。例如,在ARC-AGI通用推理测试中,HRM以2700万参数和1000个样本达到了40.3%的准确率,超越了参数更大的o3-mini-high和Claude 3.7 8K。在极端数独和30×30迷宫等任务中,HRM也展现出压倒性的优势。
尽管有观点认为HRM仍局限于特定领域,不具备广泛泛化能力,但其在推理效率、训练效率和仿脑机制方面的突破,为未来模型架构的发展提供了新思路。
值得一提的是,王冠不仅是一位年轻有为的开发者,更是GitHub上开源项目OpenChat的独立作者。他曾多次拒绝马斯克等科技巨头的邀请,选择坚持自己的技术路线,致力于挑战Transformer架构。如今,他与团队共同创办的Sapient Intelligence已获得数千万美元融资,专注于打造具备真正推理能力的下一代AI模型。
本文来源: 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号