
(由多段落组成):
近年来,视觉-语言-动作(VLA)模型成为机器人智能操控领域的研究热点,致力于将视觉感知、自然语言理解和动作执行融为一体,实现复杂环境下的自主任务完成。然而,传统训练方式高度依赖大量人工标注的演示数据,不仅采集成本高昂,且在面对新任务或未知场景时泛化能力薄弱,严重制约了其实际应用潜力。
为突破这一瓶颈,清华大学与上海人工智能实验室联合团队提出了一种全新的端到端在线强化学习训练框架——SimpleVLA-RL。该方案基于veRL强化学习架构进行深度优化,专为VLA模型设计,通过“交互式轨迹采样 + 结果奖励机制 + 探索增强策略”的三重创新,有效解决了数据稀缺、泛化不足和仿真到现实迁移难三大核心挑战。
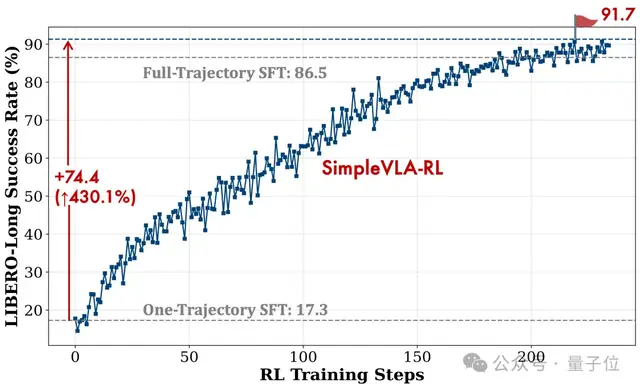
SimpleVLA-RL的核心优势在于显著降低对大规模监督数据的依赖。在仅提供单条演示轨迹(Single-Trajectory SFT)的极端低数据条件下,模型仍能通过强化学习自我迭代提升性能。实验显示,在LIBERO基准中,原本成功率仅为48.9%的OpenVLA-OFT模型,在引入SimpleVLA-RL后跃升至96.9%;而在长序列任务LIBERO-Long上,更是从17.3%飙升至91.7%,展现出惊人的数据效率与学习潜力。
该框架采用简化的二元结果奖励机制:任务成功得分为1,失败为0,并将奖励均匀分配给整条动作序列。这种设计摒弃了传统RL中繁琐的过程奖励工程,避免了跨任务调参的复杂性,同时提升了训练稳定性与可扩展性。更重要的是,它鼓励模型关注最终目标而非模仿特定动作路径,从而激发更灵活的行为策略。
为了防止模型陷入局部最优,SimpleVLA-RL引入多项探索增强技术:包括动态筛选“部分成功”轨迹以维持梯度有效性、扩大GRPO算法的裁剪区间至[0.8, 1.28]以保留潜在高价值动作、以及在rollout阶段提高采样温度至1.6来促进行为多样性。此外,团队还简化了训练目标,移除KL正则项与参考模型,进一步降低内存开销并释放探索空间。
在多个权威基准测试中,SimpleVLA-RL均刷新了当前最佳(SOTA)表现。在LIBERO单臂操控任务中,平均成功率提升至99.1%,长时序任务达98.5%;在双臂协同的RoboTwin1.0和2.0基准上,平均成功率分别从39.8%和38.3%提升至70.4%与68.8%,大幅超越π₀、UniVLA等现有模型。尤为突出的是其强大的泛化能力——在“9个已见任务训练+1个未见任务测试”设置下,SimpleVLA-RL在所有未见任务中均实现性能提升,而传统SFT方法则出现灾难性遗忘。
更令人振奋的是,该框架展现出真实世界部署潜力。即使完全使用仿真数据训练,无需任何真实机器人数据微调,SimpleVLA-RL在AgileX Piper机械臂上的平均任务成功率仍达到38.5%,较基线翻倍以上,其中“Stack Bowls”任务提升达32个百分点,“Pick Bottle”也实现了14%的成功率,验证了其卓越的Sim-to-Real迁移能力。
最引人注目的是,SimpleVLA-RL训练出的模型能够自发发现人类未曾演示的高效操作策略,例如在“Move Can Pot”任务中,模型选择用“推动”代替传统的“抓取-移动”,研究团队将其命名为“Pushcut”现象。这表明,强化学习不仅能提升性能,更能驱动模型超越人类示范,探索出更优甚至意想不到的行为路径,标志着向真正自主决策机器人迈出了关键一步。
SimpleVLA-RL不仅为VLA模型提供了高效、低成本的训练新范式,也为未来机器人自主学习、零样本迁移和开放世界适应奠定了坚实基础。相关论文已公开于arXiv,代码同步开源,欢迎开发者与研究人员共同探索下一代智能机器人的无限可能。
机器人强化学习, VLA模型, Sim-to-Real迁移, 数据效率, 泛化能力
本文来源: 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号