
第一段
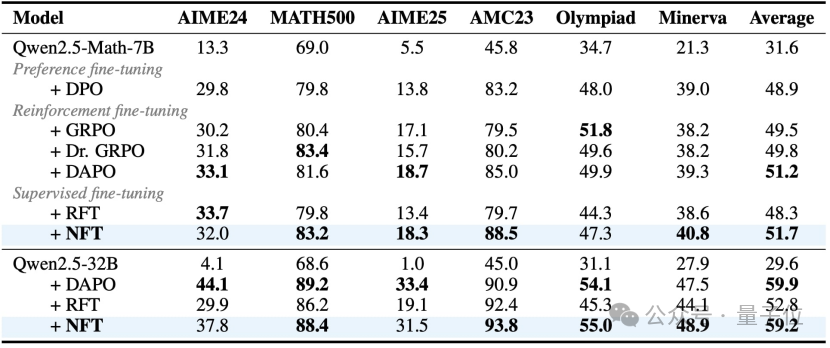
在人工智能领域,监督学习和强化学习的界限似乎正在模糊。近日,清华大学与英伟达、斯坦福大学合作提出了一种全新的监督学习方法——NFT(Negative-aware FineTuning)。这一方法通过构建“隐式负向模型”,巧妙地利用负向数据进行训练,从而显著提升模型性能,特别是在数学问题解决方面表现出色。
第二段
NFT的核心思想是将监督学习引入类似强化学习的“自我反思”机制。具体而言,该方法基于RFT(Rejection FineTuning)算法,通过构造一个“隐式负向策略”来额外利用负向数据进行训练。这并不意味着直接使用低质量数据,而是通过已知模型计算结果,结合负向数据优化正向模型。这种方法不仅缩小了监督学习与强化学习之间的差距,甚至在某些情况下实现了性能持平。
第三段
NFT的设计包含三个关键步骤:首先,数据采样阶段,语言模型生成大量数学问题答案,并通过01奖励函数区分正确与错误答案;其次,隐式策略建模阶段,利用原始模型和待训练的正向模型构建隐式负向策略;最后,在策略优化阶段,通过在正确数据上直接监督训练正向模型,同时在错误数据上通过隐式负向策略拟合优化模型。
第四段
为了进一步理解NFT的优势,可以将其与RFT对比。RFT通过丢弃错误答案,仅在高质量正向数据上进行监督训练。然而,NFT突破了这一限制,通过贝叶斯公式推导出负向数据与正向模型的关系,从而实现对负向数据的有效利用。这种“隐式负向策略”动态调整模型参数,使其适应不同难度的问题。
第五段
实验结果显示,NFT与当前最先进的强化学习算法性能相当,甚至在部分场景下更具优势。尤其是在大规模模型中,NFT表现尤为突出,表明负向反馈在大模型中的重要性逐渐显现。此外,NFT作为一种纯监督学习算法,无需依赖外部数据即可大幅提升模型的数学能力。
第六段
研究团队还发现,NFT算法能够促进模型熵的增加,鼓励模型更充分地探索可能性。这一特性为未来的研究提供了新的方向,暗示监督学习与强化学习之间可能存在更深层次的联系,有助于重新审视强化训练的本质优势。
 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号