
第一段:
只需调整两行代码,RAG(检索增强生成模型)的向量检索效率即可提升30%!这种方法不仅适用于“文搜文”、“图搜图”、“文搜图”以及“推荐系统召回”等多种任务,还具备出色的扩展性,能够支持十亿甚至百亿级别的大规模数据应用。浙江大学高云君、柯翔宇团队联合向量检索领域专家傅聪,开源了一种新方法PSP(Proximity graph with Spherical Pathway),成功解决了RAG的两大核心难题。
第二段:
传统向量检索方法大多基于欧几里得距离设计,主要关注“谁离你最近”。然而,在许多场景下,AI更需要比较的是“语义相关性”,即通过最大内积来判断“谁最相似”。过去的内积检索方法无法满足数学上的三角关系,导致许多经典算法失效。PSP创新性地发现,只需对现有图结构进行细微调整,就能找到最大内积的最优解。此外,PSP还引入了提前停止策略,能够智能判断检索是否应该终止,从而避免不必要的计算资源浪费,显著提升搜索速度。
第三段:
向量检索是支撑现代AI产品的核心技术之一,它不仅极大地扩展了传统语义检索(如关键词检索)的能力边界,还能与大模型完美结合。要充分发挥这项技术的潜力,关键在于选择合适的“度量空间”。尽管基于图的向量检索算法(如HNSW、NSG等)因其卓越的检索速度而备受青睐,但它们本质上是为欧式空间设计的。这种“度量错配”在某些场景下可能导致检索结果与查询语义无关的问题。
第四段:
在最大内积检索领域,目前尚未出现像HNSW、NSG这样现象级的算法。以往的研究往往仅在特定数据集上表现良好,但在其他数据集上效果会显著下降。研究团队通过理论探索发现,最大内积检索可以分为两种范式:一是将最大内积转换为最小欧式距离,然后利用HNSW或NSG解决;二是直接在内积空间中进行检索。前者虽然可行,但可能会导致信息损失或拓扑空间的非线性转换,从而影响检索效果;后者虽然避免了这些问题,但由于缺乏有效的空间裁剪手段,难以实现高效检索。
第五段:
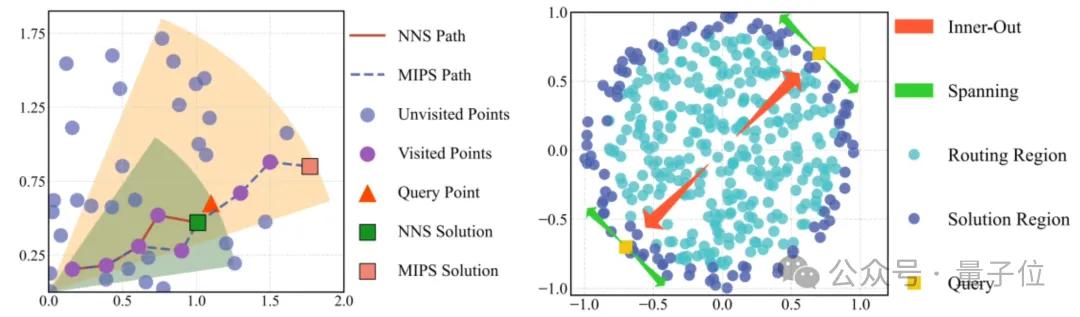
PSP研究团队深入研究后发现,即使图索引结构是为欧式距离设计的,也可以通过简单的贪心算法找到全局最优的最大内积解。基于此,团队仅需修改检索算法中的两行代码,就能实现从欧式算法到最大内积适配的转变。具体操作包括调整候选点队列的“最大堆”和“最小堆”设定,以及更改距离度量方式。
第六段:
在实际应用中,最大内积检索过程中存在大量冗余计算。研究团队通过合理引导搜索行为,有效规避了这些冗余。例如,他们发现最大内积检索的解空间通常位于数据集的“外围”,而非欧式距离最近邻可能出现在数据空间的任意位置。因此,PSP设计了针对性策略,使搜索起始点尽量接近目标区域。此外,团队还提出了自适应“早停”策略,通过训练决策树来判断搜索何时应终止,从而进一步优化性能。
第七段:
为了验证PSP算法的效果,研究团队在8个大规模、高维度的数据集上进行了充分测试。结果显示,PSP在相同召回率下的检索速度显著优于现有方法,且性能稳定。特别是在MNIST数据集上,PSP的速度比第二名快4倍以上。此外,PSP展现出强大的泛化能力,适用于“文搜文”、“图搜图”、“文搜图”以及“推荐系统召回”等多种数据模态。在可扩展性方面,PSP的时间复杂度接近log(N),能够在十亿乃至百亿级别的数据规模上实现高效检索。
 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号