
(由多段落组成):
在大语言模型飞速发展的今天,Retrieval-Augmented Generation(RAG)技术已成为提升模型事实准确性与信息时效性的关键路径。然而,尽管RAG已被广泛应用,其在面对人类语言丰富表达方式时仍显乏力——尤其是当同一问题以不同词汇呈现时,检索系统容易“误判”,导致生成结果偏离真实答案。针对这一长期被忽视的痛点,来自北京航空航天大学、北京大学及中关村实验室的联合研究团队,在ACL 2025上提出了一项突破性工作:Lexical Diversity-aware RAG(简称DRAG),首次将“词汇多样性”系统化地融入RAG框架中,显著提升了问答系统的鲁棒性与准确率。
第一个核心组件是 Diversity-sensitive Relevance Analyzer(DRA),它通过细粒度语义拆解实现更智能的相关性判断。DRA将查询划分为三类语义单元:不变词(如专有名词)、可变词(同义替换频繁的功能词)和补充信息(上下文增强)。对于不变词,要求严格匹配;对于可变词,则利用大模型的语义理解能力进行灵活扩展比对;而对于补充信息,则根据任务需求动态判断是否采纳。基于此分析,系统会对初始检索结果重新排序,输出更具解释力的多维相关性评分,有效减少“假相关”文档的干扰。
第二个关键模块是 Risk-guided Sparse Calibration(RSC),专注于生成阶段的风险控制。即使检索到高质量文档,模型仍可能因注意力偏移或词汇误导而生成错误。RSC通过实时监测三个维度的风险——词汇风险(是否依赖低相关词)、注意力风险(关注点是否偏离核心证据)、预测风险(当前输出是否与检索冲突)——来识别潜在偏差。其独特之处在于“稀疏校准”机制:仅对高风险token进行微调,而非全局重写,从而在保证生成流畅性的同时提升准确性,实现了效率与质量的平衡。
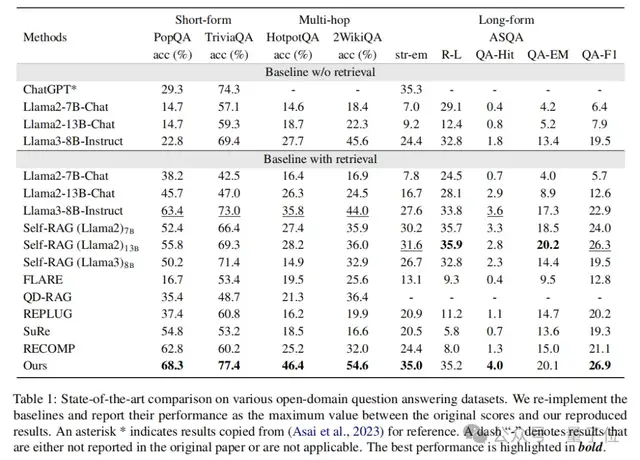
实验结果显示,DRAG在多个主流开放域问答基准上均取得显著提升。在PopQA和TriviaQA等短答案任务中,准确率分别提高4.9%和4.4%;而在更具挑战性的多跳推理任务HotpotQA和2WikiMultiHopQA上,性能跃升10.6%,刷新当前最优水平(SOTA)。在长文本生成任务ASQA中,也在str-em和QA-F1等指标上创下新纪录。更重要的是,该方法展现出极强的通用性,适用于Llama2-7B、Llama2-13B、Qwen2-7B、Alpaca-7B、Mistral-7B等多种主流模型架构,证明其轻量且易于集成。
DRAG不仅是一项技术改进,更是对RAG本质的一次深入思考:让AI真正理解“言外之意”。未来,研究团队计划将该框架拓展至医疗、法律、金融等专业领域,推动大模型从“读取信息”向“深度理解”迈进。随着代码即将开源(GitHub: https://github.com/Zhange21/DRAG),这一成果有望成为下一代RAG系统的标准组件之一。论文全文已收录于ACL 2025会议论文集,可通过以下链接获取:https://aclanthology.org/2025.acl-long.1346/
(关键词用逗号间隔分隔):
RAG, 词汇多样性, 检索增强生成, ACL 2025, 大模型问答
 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号