
(由多段落组成):
2025年,小米在AI领域的布局进入加速期。从年初传出天才女科学家罗福莉与雷军接触、随后离职原单位,到11月正式官宣加入小米,再到12月18日亮相“人车家全生态大会”并发布全新大模型MiMo-V2-Flash,这位被誉为“AI天才少女”的年轻专家迅速成为行业焦点。她带来的不仅是一个技术成果,更是小米全面进军人工智能时代的关键信号。这款参数规模达309B、激活参数仅15B的模型,虽被罗福莉自嘲“不算真正的大模型”,却在性能与效率之间找到了惊人的平衡点。
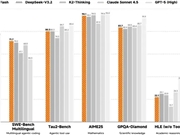
MiMo-V2-Flash的核心定位是为智能体(Agent)提供高效基座。不同于一味追求参数膨胀的“大力出奇迹”路线,小米选择了高性价比、低延迟、强交互的发展路径。该模型实现了每秒150 tokens的生成速度,推理成本仅为Claude Sonnet 4.5的2.5%,而输出价格低至2.1元/百万tokens,在国内同类产品中极具竞争力。尤其在代码能力和工具调用方面表现突出,SWE-Bench Multilingual测试中甚至超越GPT-5等闭源模型,跻身全球开源模型Top1-2行列,多项基准已比肩DeepSeek-V3、Kimi K2-Thinking和通义千问Qwen系列。
然而,新模型的发布也引发了业内争议。一部分观点认为其在特定榜单上的优异表现存在“刷分”嫌疑,质疑其泛化能力;但更多业内人士认可其在轻量化与端侧适配上的战略意义。尤其是在当前Scaling Law边际效益递减的背景下,小米另辟蹊径——将重心从预训练转向后训练(Post-train),通过强化学习激发模型潜能,并构建稳定训练范式,以支撑未来更复杂的AI代理系统。
为实现极致推理效率,小米采用了创新的混合注意力机制:采用5:1比例的滑动窗口注意力(SWA)与全局注意力(GA)结合结构。实验显示,SWA在长文本处理和逻辑推理上优于主流线性注意力,且KV Cache固定大小,易于对接现有算力基础设施。这一架构选择不仅提升了响应速度,也为后续部署至手机、汽车等终端设备打下基础。尽管309B的体量仍难以直接运行于端侧,但这标志着小米正朝着“端云协同”的方向稳步推进。
更重要的是,小米对AI的战略规划早已超越单一模型的竞争。从2025年起,公司密集推出MiMo系列产品矩阵:4月开源MiMo-7B系列,涵盖基础、指令微调及RL版本;5月上线多模态模型MiMo-VL-7B,增强视觉理解能力;11月发布具身智能模型MiMo-Embodied,打通自动驾驶与机器人技术壁垒;最终以MiMo-V2-Flash收尾,聚焦Agent底层支撑能力。这一连串动作背后,是实打实的资金投入——小米总裁卢伟冰透露,2025年研发投入将超300亿元,其中约75亿专项用于AI,未来五年总投入预计突破2000亿元。
组织架构上,小米同样动作频频。自2024年起搭建专属AI Infra平台,并筹建万卡级GPU集群,初始即拥有6500张高性能显卡资源。人才方面,除罗福莉领衔基础模型团队外,还引入智驾专家陈龙,形成“双核驱动”格局。双方合作推出的MiMo-Embodied模型,是全球首个实现跨具身(X-Embodied)能力的开源基座,推动知识在自动驾驶与机器人间的迁移复用,体现小米试图用统一AI框架连接“人-车-家”生态的野心。
雷军曾强调,小米的AI战略核心是“轻量化+本地部署”。依托全球累计连接超10亿台设备的庞大硬件网络,小米的目标不是做最炫技的模型,而是让AI真正落地到每一部手机、每一辆汽车、每一个智能家居场景中。通过升级“超级小爱”语音助手与澎湃OS系统,使终端具备主动服务与持续学习的能力;在智能驾驶领域,则依赖大模型作为认知中枢,提升环境感知与决策水平。
正如罗福莉在演讲结尾所言:“AI进化的下一个起点,必须是一个能与真实世界互动的物理模型。”这暗示着小米未来的两大技术主线:一是深耕端侧轻量模型,普及本地智能;二是构建具备时空连续性与物理一致性的虚拟仿真系统,服务于自动驾驶训练与数字孪生应用。MiMo-V2-Flash不仅是技术成果,更是小米向资本市场讲述的新故事——一家硬件巨头,正借助高效AI大脑与广泛终端触角,在智能时代完成自我重塑。成败关键,不在排行榜名次,而在这些技术能否真正融入用户日常,带来可感知的智能体验跃迁。
小米AI, MiMo-V2-Flash, 罗福莉, 智能驾驶, 端侧大模型
本文来源: 光锥智能公众号【阅读原文】
光锥智能公众号【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号