
当然可以!以下是根据你提供的文章,进行整理后的版本,采用人工撰写风格,并优化了SEO结构,使其更符合搜索引擎优化策略,包括多段落结构、关键词自然嵌入、语义通顺、逻辑清晰。
## (由多段落组成)
DeepSeek V3.1 版本更新亮点与争议并存
近日,DeepSeek 正式发布了其最新版本 V3.1,虽然这是一次小幅度的模型更新,但依然带来了不少值得关注的新特性。新版本引入了混合推理架构,支持“思考模式”与“非思考模式”的自由切换,显著提升了推理效率,最高可达 50% 的性能优化。此外,模型还兼容 128K 的长上下文处理能力,进一步拓展了其应用场景。
在模型优化方面,DeepSeek V3.1 还引入了 UE8M0 FP8 参数精度格式,有效降低了内存占用率,最高可节省 75% 的资源消耗。值得一提的是,该版本还完成了对国产新一代芯片的适配,大幅减少了对国外 GPU 的依赖,提升了模型在国内生态中的部署灵活性。
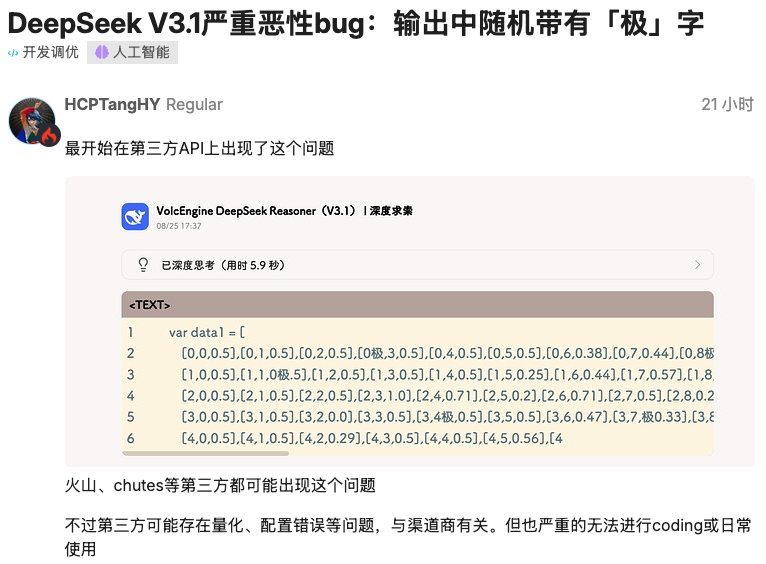
“极”“极速”等 token 随机出现,引发开发者关注
尽管 DeepSeek V3.1 在性能和资源利用方面表现出色,但在实际使用过程中,一些开发者却发现了一个令人困惑的问题:模型在生成文本时,会随机插入诸如「极」、「極」、「极速」、「extreme」等 token,且出现的概率具有一定的随机性。
这一问题最初在火山引擎、Chutes 等第三方 API 平台上被用户发现。例如,有开发者在使用 VolcEngine 调用 DeepSeek V3.1 整理物理试卷时,输入中意外出现了“极板”等词汇。此外,硅基 API 和腾讯新推出的 Codebuddy AI 编程工具中也出现了类似问题,甚至在 UI 界面中被自动添加了“极速赛车开奖”、“极速电竞”等明显不相关的关键词。
官网与第三方平台均受影响,问题非偶然
起初,一些开发者猜测这可能是由于第三方平台在模型量化、部署配置或硬件兼容性方面存在问题,属于偶发性 Bug。然而,随着越来越多用户在不同平台和环境中进行测试,问题逐渐浮出水面——即使是 DeepSeek 官方网站,也存在相同的 token 异常现象。
尽管在官方平台上出现的概率相对较低,但在第三方服务中这一问题更为频繁。更令人担忧的是,一旦模型生成了这些异常 token,后续输出中出现的概率还会进一步增加,形成一种“雪崩效应”。
Reddit 与知乎用户实测反馈,问题或非单一模型所致
在 Reddit 上,用户 @notdba 发帖详细描述了他在使用 DeepSeek V3.1 时遇到的问题,并提供了多个测试案例。例如,在本地运行的 ik_llama.cpp 模型中,期望输出“time.Second”,但实际结果却出现了“time.Se极”或“time.Se extreme”等异常结果。
此外,用户还在 Fireworks 提供的 FP8 全精度模型中复现了该问题,排除了量化处理导致的可能性。进一步测试发现,Novita 平台也存在类似问题,表明这并非单一推理栈的问题。
更值得关注的是,@notdba 在测试其他模型时发现,Qwen3 系列的部分版本也出现了类似的异常 token 输出现象,怀疑这些模型可能使用了相同来源的训练数据,从而导致了相似的问题。
数据集污染 or 模型训练“捷径”?
目前,DeepSeek 官方尚未对这一问题作出正式回应。技术社区中,关于问题根源的讨论主要集中在两个方向:
1. 数据集污染:可能在数据清洗阶段未能彻底过滤掉包含异常字符或特殊模式的数据,导致模型在训练过程中学习到了错误的语义关联。
2. 模型训练“捷径”:在面对不确定的上下文时,模型倾向于选择邻近或高频 token 作为输出,从而形成了“极”或“extreme”等异常 token 的随机插入现象。
知乎用户 @AI 解码师 指出,这类问题可能源于训练数据或蒸馏链条中的残留瑕疵。例如,模型在预训练或 SFT 阶段接触到了“极长的列表”等表达方式,将其误认为是某种语义边界符。这种模式一旦被强化,就可能在推理阶段被随机触发。
问题影响与后续展望
虽然这类异常 token 的触发概率较低,但在大规模使用场景下,其影响不容忽视。尤其在编程、结构化输出等对结果准确性要求较高的任务中,这类问题可能导致代码错误、数据失真等严重后果。
目前,社区仍在等待 DeepSeek 官方对这一问题的回应与修复方案。同时,这也提醒我们,大语言模型本质上是基于统计规律进行预测,其“理解”能力仍依赖于训练数据的质量与完整性。
##
本文来源: iFeng科技【阅读原文】
iFeng科技【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号