
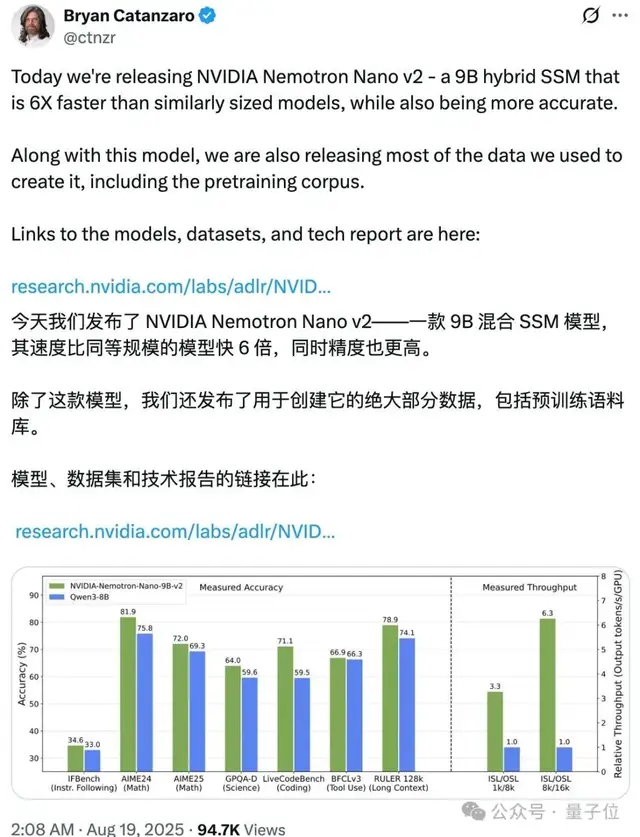
这款模型参数规模为9B(90亿),虽然体积小巧,但性能却不容小觑。根据技术报告,其在复杂推理任务中的准确率与Qwen3-8B相当甚至更优,同时在处理速度上提升了6倍。
与当前主流的大模型不同,Nemotron Nano v2的设计初衷是打造一个兼顾推理与非推理任务的统一模型。这意味着它不仅适用于日常的问答与指令执行,还能胜任逻辑推理、数学计算等高难度任务。英伟达还引入了“思考预算控制”功能,用户可以设定模型在推理过程中使用的token数量,从而在速度与准确性之间取得平衡。
值得一提的是,该模型支持跳过中间推理步骤,直接输出最终答案。不过,这种方式在面对复杂任务时可能会导致准确率下降。因此,建议在需要深度分析的场景下,启用完整的推理流程。
在训练方面,Nemotron Nano v2采用了20万亿token的预训练数据,使用FP8精度进行训练,并通过Warmup-Stable-Decay学习率调度策略优化训练过程。随后,模型还经历了持续预训练的长上下文扩展阶段,使其能够支持高达128k token的上下文长度。
后训练阶段则包括监督微调(SFT)、组相对策略优化(GRPO)、直接偏好优化(DPO)和人类反馈强化学习(RLHF)等多种方法,以提升模型的对齐性和指令遵循能力。其中,约5%的数据包含故意截断的推理轨迹,用于实现细粒度的思考预算控制。
为了提升模型在边缘设备上的运行效率,英伟达还对模型进行了剪枝与蒸馏处理。最终版本的Nemotron Nano v2可以在单个NVIDIA A10G GPU上运行,并支持128k token的上下文长度,非常适合部署在资源受限的设备上。
除了模型本身,英伟达还开源了两个基础版本:NVIDIA-Nemotron-Nano-12B-v2-Base(对齐或剪枝前的基础模型)和NVIDIA-Nemotron-Nano-9B-v2-Base(剪枝后的基础模型),方便研究人员和开发者根据需要进行定制和优化。
更令人瞩目的是,英伟达还首次公开了用于训练Nemotron Nano v2的66万亿token预训练语料库。该数据集被细分为四个高质量子集:
– Nemotron-CC-v2:涵盖2024至2025年的Common Crawl网络快照,经过去重和合成改写,支持多语言推理。
– Nemotron-CC-Math-v1:专注于数学,包含1330亿token的数学数据,标准化为LaTeX格式,保留代码与公式。
– Nemotron-Pretraining-Code-v1:来自GitHub的高质量代码数据集,覆盖11种编程语言。
– Nemotron-Pretraining-SFT-v1:综合生成的SFT数据,涵盖STEM、学术、推理和多语言领域。
英伟达表示,这些数据集的发布将为小型语言模型的发展提供坚实的基础。此外,他们还提供了一个小型抽样版本,方便开发者快速上手测试。
英伟达近年来在开源领域动作频频,与部分国外科技公司闭源的趋势形成鲜明对比。无论是Llama Nemotron Super v1.5,还是此次推出的Nemotron Nano v2,都显示出其在AI开源生态建设上的坚定步伐。
目前,Nemotron Nano v2已经开放在线试用,感兴趣的开发者和研究人员可以通过官方链接进行体验和下载模型。
本文来源: 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号