
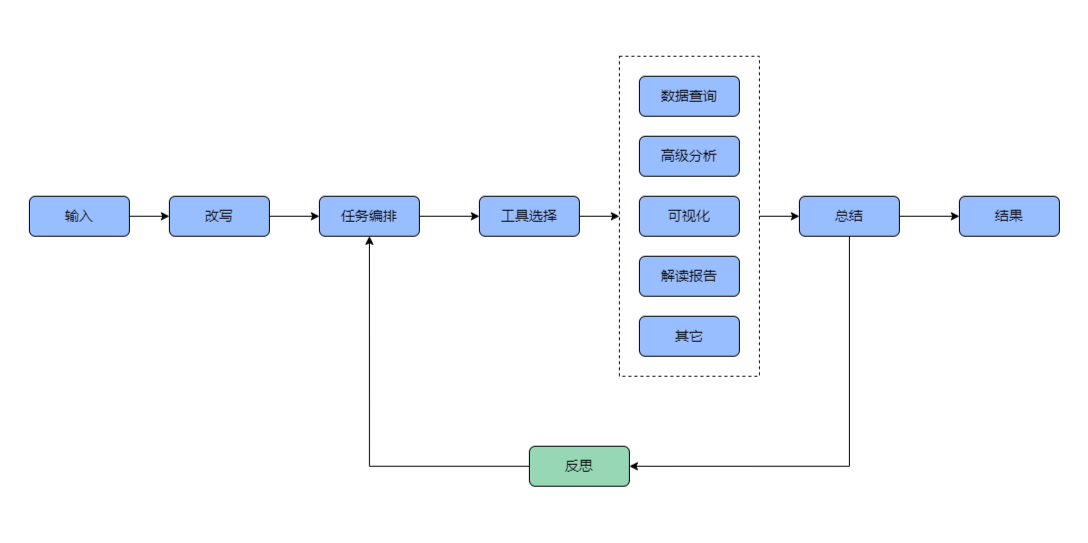
整体评测:Qwen3与DeepSeek-R1在数据分析领域的对比分析
随着AI技术的快速发展,大模型在企业级数据分析和智能决策场景中的应用越来越广泛。近日,阿里巴巴开源了新一代通义千问模型Qwen3,而数势科技的数据分析智能体SwiftAgent也迅速完成了对Qwen3的全面适配,并发布了详细的测评报告。本文将从多个维度对比Qwen3与DeepSeek-R1的表现。
一、上下文改写
在实际应用中,用户输入的查询语句往往不够规范,因此需要对输入语句进行改写以提高准确性。测试结果显示,在不同的语境下,Qwen3-32B表现尤为突出,尤其是在不需要改写的场景中,其判断更为精准。相比之下,其他模型在某些情况下可能会误判或继承上一轮导致错误。
二、任务编排与工具调用
数据分析任务通常需要拆解成多个子任务来完成。在这一环节,Qwen3-32B和Qwen3-235B-A22B表现出色,能够准确识别并调用所需的工具,从而提高最终结果的准确性。而Qwen2.5-72B则明显落后,无法成功拆解任务,甚至在某些步骤中遗漏关键工具的调用。
三、数据查询
数据查询是数据分析的核心环节之一,尤其是对时间要素的识别能力至关重要。Qwen3-32B在时间推理方面已接近DeepSeek-R1的效果,远超Qwen2.5-72B。此外,在实体抽取方面,Qwen3-32B的Dense模型效果优于其他模型,显示出更强的语义理解能力。
四、图表生成
图表生成是展示数据分析结果的重要手段。Qwen3-32B在这一环节表现出色,不仅能够准确生成代码,还能避免数据遗漏的问题。尽管在渲染排版上略逊于Qwen3-235B-A22B和DeepSeek-R1,但整体效果依然令人满意。
五、总结反思
针对生成的错误代码,大模型是否能够结合错误反思并生成准确的代码是一个重要指标。Qwen3的两个模型在数据类型处理上表现最为合理,优先尝试转换为数值,无法强制转换时才选择抛弃。经过二次提示优化后,所有模型均能给出优化方案,达到预期效果。
此外,在数学计算推理能力方面,DeepSeek-R1模型和Qwen3-235B-A22B表现优异,符合Scale Law的认知。
六、综合评价
总体来看,Qwen3模型在数据分析Agent构建方面具有显著优势。无论是任务规划、代码生成、数学计算还是语义识别等方面,Qwen3都表现出色。特别是Qwen3-32B模型,不仅远优于上一代模型,而且部署成本更低,消费级显卡即可实现推理自由,为企业使用大模型提供了更高的性价比。
数势科技SwiftAgent率先完成对Qwen3的全面适配,并对中间环节进行了能力升级和创新性功能开发,为企业客户提供更高性能、更低成本的智能产品。
本文来源: 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号