
(由多段落组成):
苹果公司近期在人工智能与可穿戴设备融合领域再进一步。据科技媒体9to5Mac于11月21日报道,苹果在其最新发布的研究报告中提出了一项创新技术——“后期多模态传感器融合”(Late Multimodal Sensor Fusion),该技术有望未来应用于Apple Watch等智能穿戴设备中,实现更精准的用户活动识别。
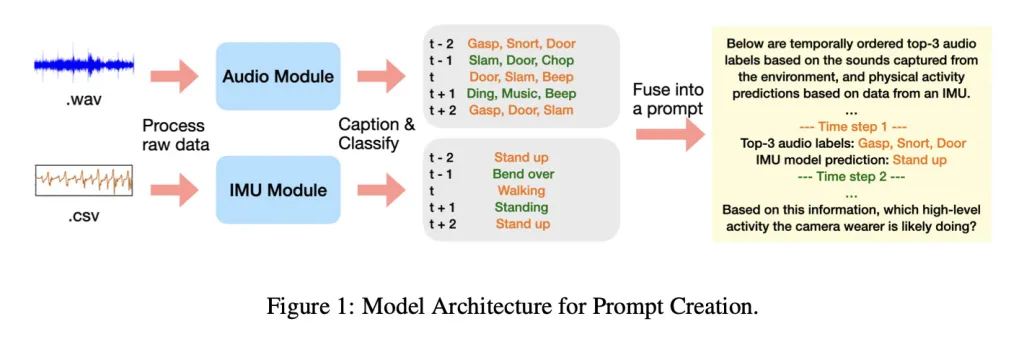
这项技术的核心在于将大语言模型(LLM)的强大语义理解能力与传统传感器数据相结合。不同于直接处理原始音频或运动信号的方式,苹果的研究团队采用了一种更加隐私友好的路径:通过小型专用模型先将传感器采集到的音频和动作信息转化为自然语言描述,例如“水流声”或“正在切菜”,再将这些文本输入给大语言模型进行综合推理,从而判断用户当前正在进行的具体活动。
这种方法巧妙地规避了敏感原始数据的暴露风险,极大提升了用户隐私保护水平。同时,它也展示了大语言模型在跨模态信息整合方面的潜力——即使没有经过特定任务训练,LLM依然能够基于文本化的感官描述,准确推断出复杂的生活场景。
为了验证这一方法的有效性,研究团队采用了Ego4D数据集,该数据集包含了数千小时的第一人称视角视频记录。研究人员从中提取了12种常见日常行为样本,如吸尘、烹饪、洗碗、打篮球、举重等,每段持续约20秒,并利用轻量级模型生成对应的环境与动作文本描述。随后,这些文本被输入至多个主流大语言模型,包括谷歌的Gemini-2.5-pro和阿里的Qwen-32B,在“零样本”与“单样本”两种模式下测试其识别准确率。
实验结果令人振奋:即便在没有任何示例参考的情况下,大语言模型的表现仍显著优于随机猜测,F1分数表现优异;而在提供一个示例后,识别准确率进一步提升。这表明LLM具备强大的泛化能力和上下文学习能力,能够在缺乏专门训练的前提下完成复杂的多模态推理任务。
更重要的是,这种“后期融合”策略避免了为每个应用场景单独开发定制化AI模型的需求,大幅降低了内存占用和计算开销,特别适合资源受限的移动和可穿戴设备。苹果方面还公开了相关实验数据与代码,鼓励学术界复现与拓展该研究,推动多模态AI技术的发展。
随着AI技术不断向终端设备下沉,苹果此次探索不仅为智能手表的功能升级提供了新思路,也为未来个性化健康监测、情境感知服务奠定了技术基础。可以预见,未来的Apple Watch或将不仅能记录步数和心率,还能真正“理解”你正在做什么。
大语言模型, Apple Watch, 多模态融合, 活动识别, 人工智能
本文来源: IT之家【阅读原文】
IT之家【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号