
(由多段落组成):
近年来,扩散模型在图像生成领域大放异彩,但其发展路径似乎逐渐偏离了最初的“去噪”本质。何恺明团队最新发表的论文提出一个颠覆性观点:当前主流的扩散模型训练方式可能存在根本性偏差——我们一直在让模型预测噪声,而不是直接学习如何还原清晰图像。这一研究不仅挑战了行业惯例,也重新唤起了人们对扩散模型底层逻辑的思考。
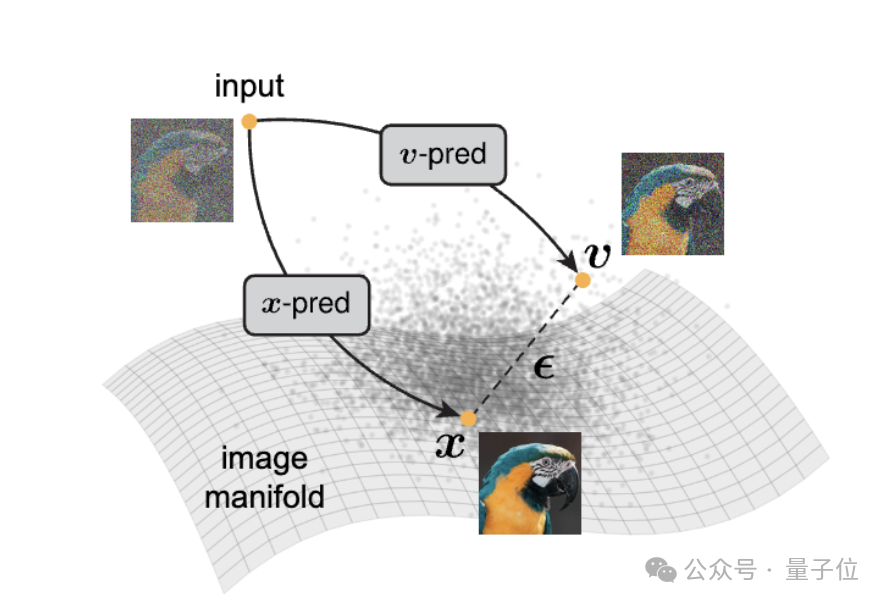
与当前普遍采用的“预测噪声”策略不同,该团队提出了一种极简却高效的新型架构——JiT(Just image Transformers),主张让神经网络直接输出干净图像。他们认为,自然图像数据其实分布在高维空间中的低维流形上,具有内在结构和规律;而噪声则是均匀分布在整个空间中的无序信息,缺乏可学习的模式。因此,让模型去拟合随机噪声,本质上是在强迫它记忆高维混乱数据,这对模型容量要求极高,容易导致训练不稳定甚至崩溃。
相比之下,直接预测原始图像相当于引导模型将带噪输入“投影”回数据流形,更符合神经网络擅长提取结构化特征的特性。这种思路回归了“去噪”的本源,也让整个训练过程更加高效、稳定。尤其是在处理大尺寸Patch(如32×32或64×64)时,传统方法因维度爆炸而性能急剧下降,FID指标飙升;而JiT凭借其直接建模图像的能力,在超高维输入下依然保持优异表现,展现出强大的扩展潜力。
JiT的设计极度简洁:不依赖VAE压缩潜空间,无需Tokenizer进行离散化处理,也不引入CLIP、DINO等外部预训练特征对齐机制,更没有使用感知损失或其他复杂辅助目标函数。它从原始像素出发,像标准ViT一样将图像切分为大块Patch并输入Transformer结构,唯一的关键改变是——输出目标不再是噪声残差,而是完整的干净图像块本身。正是这种“返璞归真”的设计理念,使得模型在ImageNet 256×256和512×512分辨率任务中分别取得了1.82和1.78的FID成绩,达到当前最先进水平(SOTA)。
值得一提的是,研究还发现人为引入降维瓶颈层非但未削弱性能,反而提升了生成质量。这进一步验证了“流形学习+噪声过滤”的有效性——适度压缩信息通道有助于模型聚焦于核心结构,抑制无关扰动。这也为未来轻量化生成模型的设计提供了新方向。
本论文的第一作者黎天鸿是何恺明教授的首位博士后研究员,本科毕业于清华大学姚班,后于MIT获得硕博学位。他的研究聚焦于表征学习与生成模型的融合,致力于构建超越人类感知能力的视觉智能系统。此前他曾与何恺明共同提出自条件生成框架RCG,并参与多项重要研究。除了学术成就外,他还是一位热爱湖南菜的美食爱好者,个人主页上甚至公开分享了自己的私房菜谱。
这项工作不仅是技术上的突破,更是方法论上的反思:当AI研究越来越追求复杂结构与工程技巧时,或许真正的进步来自于回归问题本质。正如ResNet和MAE所展现的那样,何恺明一贯倡导“大道至简”的科研哲学,这一次,他再次用最朴素的思想撼动了生成模型的主流范式。
扩散模型, 何恺明, JiT, 图像生成, 去噪
本文来源: 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号