
(由多段落组成):
在人工智能爆发式发展的2025年,一场关于“算力消耗”的暗战正在悄然上演。近日,OpenAI首次曝光其全球范围内Tokens消耗破万亿级别的企业客户名单,一份被称为“万亿Tokens俱乐部”的神秘榜单浮出水面,揭示了哪些公司在真正大规模落地大模型技术。
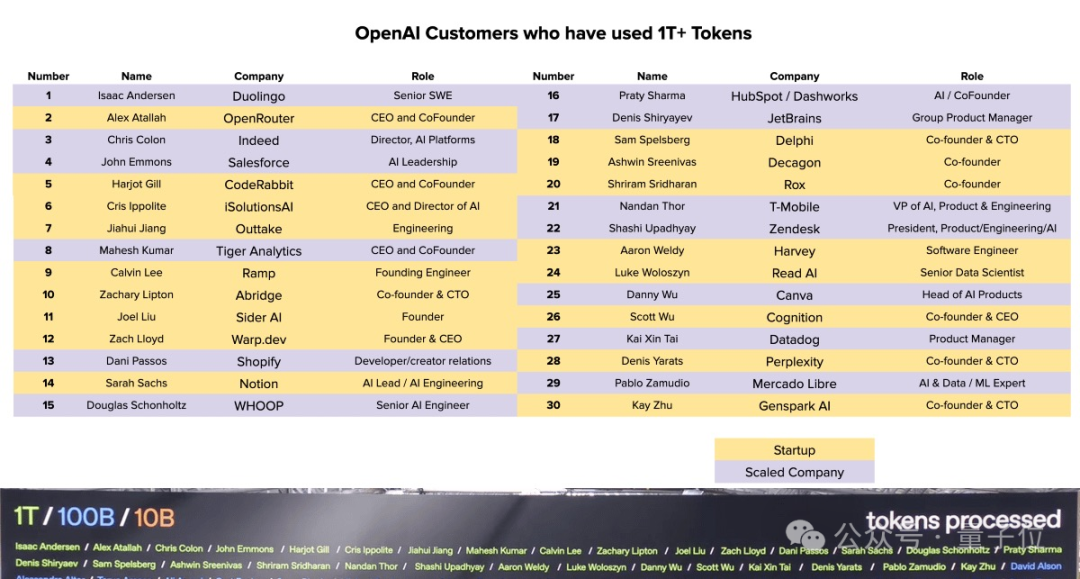
这份名单中共有30家企业,涵盖了教育、电商、设计、法律、医疗、招聘等多个领域,几乎囊括了当前AI应用最前沿的代表性公司。榜单中既有像Duolingo、Canva、Salesforce这样的行业巨头,也不乏Cognition、Rox等新兴AI初创力量。值得注意的是,这些企业的共同点是——它们都不是简单地“试用”AI,而是将大模型深度集成到核心产品流程中,形成高频、高复杂度的调用场景。
从视觉上看,榜单采用黄紫双色标注:黄色代表初创公司,紫色代表已规模化运营的企业,两者数量接近持平,显示出大模型的应用正从科技巨头向创新型企业快速扩散。虽然名单按对接人姓氏排序并无名次之分,但背后却隐藏着真实的AI使用强度图谱。其中,Duolingo、OpenRouter、Canva和Perplexity四家公司尤为突出,堪称“Tokens吞噬巨兽”。
以语言学习平台多邻国(Duolingo)为例,这只看似萌态十足的猫头鹰早已成为AI驱动教育的先锋。自2023年推出基于GPT-4的Duolingo Max以来,平台便实现了从题目生成、错题解析到情景对话模拟的全链路智能化。数亿用户的日常互动带来了海量请求,使其长期位居OpenAI API调用量前列。
而OpenRouter则走出了另一条路径——它不直接面向终端用户,而是打造了一个统一调用GPT、Claude、Gemini等主流大模型的“AI路由器”。开发者只需一套接口即可自由切换不同模型,极大降低了多模型集成门槛。这种平台化架构让它迅速成长为Tokens分发中枢,堪称“模型即服务”时代的基础设施典范。
同样令人震惊的是在线设计平台Canva。自引入AI图像生成、智能排版与视频合成功能后,其创作流程变得极度依赖多模态推理。每一次海报生成或模板优化都涉及文本理解、视觉渲染与布局决策的多重模型调用,导致单次操作的Token消耗远超纯文本任务,最终累积成惊人的总量。
更值得警惕的是AI搜索引擎Perplexity。它的搜索逻辑并非传统关键词匹配,而是通过LLM对多个网页进行嵌入、摘要与可信度评估,每一轮查询背后都是数十次小规模模型调用。随着月活用户突破2000万,其整体Token消耗密度甚至可与ChatGPT相媲美,成为名副其实的“隐形吞金兽”。
为什么这些公司能“吃下”如此庞大的Tokens?根本原因在于三点:一是超高频交互,如Notion、Duolingo等工具类App用户每日多次使用;二是任务高度复杂,涉及多模态处理或多步骤推理,如Canva的设计流、Harvey的法律分析;三是平台聚合效应,像OpenRouter、Warp.dev这类中间层平台,将分散需求集中调度,形成流量放大器。
如今,业内开始用一个新指标来衡量AI真实落地程度——日均10亿Tokens消耗量。这一数字正逐渐取代融资额、估值等虚高指标,成为判断一家企业是否真正实现AI规模化的核心标准。有人称之为“Tokens独角兽”,意指那些不靠讲故事、而靠实际算力消耗证明价值的实干派。
可以预见,在未来的大模型竞争中,谁掌握了高效、可持续的Tokens使用能力,谁就掌握了通往AGI时代的关键入口。而这份名单,正是当下AI产业最真实的“用电量排行榜”。
本文来源: 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号