
今天凌晨,Meta正式对外开源了其最新研发的视觉大模型——DINOv3,再次引起AI圈广泛关注。作为DINO系列的第三代模型,DINOv3在训练方式、模型架构、任务覆盖范围等多个方面进行了全面升级,展现出强大的泛化能力和实用性。
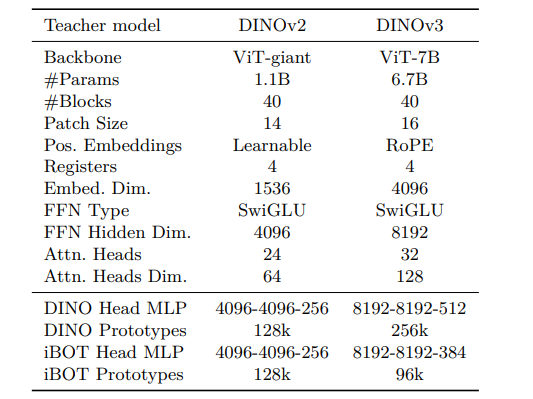
与传统视觉模型依赖大量人工标注数据不同,DINOv3采用了自我监督学习机制,极大降低了训练所需的数据标注成本与计算资源。此外,其训练数据规模也显著扩大,达到了惊人的17亿张图像,相比前代模型提升了12倍;同时,模型参数量也增至70亿,比DINOv2高出7倍。
多任务性能全面领先,广泛适用于多个行业
在多个视觉任务的测试中,DINOv3均表现卓越。测试覆盖了图像分类、语义分割、单目深度估计、3D理解、实例识别、视频分割跟踪、视频分类等10大类、60多个子任务,均超越了当前主流的开源与闭源模型。
这种强大的视觉理解能力,使其在医疗影像分析、环境监测、自动驾驶、航空航天等多个领域具备广泛的应用潜力。例如,在单目深度估计方面,DINOv3的性能提升对自动驾驶系统感知环境至关重要;在遥感图像分析中,其高精度的地理信息识别能力也为生态监测和灾害评估提供了新思路。
模型架构创新:更大参数、更强适应性
DINOv3采用了定制化的Vision Transformer架构,嵌入维度从1536提升至4096,注意力头数从24增加到32,前馈网络的隐藏维度也扩展至8192,整体模型表达能力更强。此外,DINOv3引入了旋转位置嵌入技术,替代传统的可学习位置嵌入,使模型能更灵活地适应不同分辨率输入。
为解决大规模训练中常见的优化周期不稳定问题,DINOv3取消了传统的余弦调度策略,转而采用恒定超参数调度,提高了训练稳定性。
创新技术:Gram锚定与特征稳定性增强
在长时间训练中,模型的特征图可能会出现退化现象。为此,DINOv3提出了一种全新的Gram锚定技术,通过保持学生模型与教师模型在特征Gram矩阵上的相似性,来维持特征之间的结构一致性。
在具体实现上,DINOv3将高分辨率图像输入教师模型,并通过双三次插值下采样至学生模型输出尺寸,保留更精细的空间信息。训练过程中,每10,000次迭代更新一次教师模型,仅在100万次迭代后启用Gram锚定,有效提升了密集任务的性能表现。
多重后处理优化,提升部署灵活性
为了增强模型在实际应用中的适应性,DINOv3引入了三大后处理优化策略:
1. 高分辨率适配:通过混合分辨率训练,使模型在4096×4096等超大分辨率输入下仍能保持特征稳定。在1024×1024分辨率下,语义分割性能提升15%。
2. 知识蒸馏:将70亿参数模型的知识蒸馏到小型模型中,形成包括ViT-S、ViT-B、ViT-L及ConvNeXt系列的模型家族,满足从边缘设备到高性能服务器的多样化部署需求。
3. 文本对齐优化:冻结视觉主干网络,训练文本编码器与视觉特征对齐,实现零样本任务能力。在COCO图像-文本检索任务中,图像到文本的Recall@1达到84.7%。
多项任务性能全面超越前代模型
在ADE20k语义分割任务中,DINOv3的线性探针mIoU达到55.9,远超DINOv2的49.5;在Cityscapes数据集上,mIoU为81.1,显著优于AM-RADIOv2.5的78.4。
在深度估计方面,DINOv3在NYUv2数据集上的RMSE为0.309,优于DINOv2的0.372;在KITTI数据集中,RMSE为2.346,接近专门的深度估计模型Depth Anything V2。
在3D关键点匹配任务中,DINOv3在NAVI数据集上的召回率达到64.4%,超过DINOv2的60.1%;在SPair数据集中,其性能领先同类模型2-5个百分点。
此外,在图像分类、跨分布泛化、细粒度识别、实例检索等任务中,DINOv3也展现出强大的竞争力,多项指标接近甚至超越弱监督模型水平。
视频与遥感任务中的出色表现
DINOv3在视频分割跟踪任务中同样表现出色。在DAVIS 2017数据集上,其高分辨率下的性能达到83.3,远超DINOv2的76.6;且随着分辨率提升,性能稳定增长,而其他模型在高分辨率下性能反而下降。
在遥感与地理空间任务中,DINOv3在Open-Canopy树冠高度估计任务中MAE为2.02米,优于现有方法;在肯尼亚地区的实际应用中,误差从4.1米降至1.2米,显著提升了测量精度。
在GEO-Bench遥感任务中,DINOv3的平均准确率为81.6%,刷新了多项遥感分类与分割任务的纪录。
开源地址与开发者反馈
DINOv3已正式开源,相关模型和代码可在以下平台获取:
– HuggingFace地址:[https://huggingface.co/collections/facebook/dinov3-68924841bd6b561778e31009](https://huggingface.co/collections/facebook/dinov3-68924841bd6b561778e31009)
– GitHub地址:[https://github.com/facebookresearch/dinov3](https://github.com/facebookresearch/dinov3)
不少开发者表示,DINOv3的强大视觉能力甚至让人期待其与Llama大语言模型的结合,以弥补Llama当前在视觉理解方面的不足。
本文来源: iFeng科技【阅读原文】
iFeng科技【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号