
整理后文章
近日,阿里云正式发布了其大模型 Qwen3 的最新版本——Qwen3-235B-A22B-Instruct-2507-FP8,引发业界广泛关注。此次更新标志着 Qwen 系列模型在训练策略上的重大调整。据官方介绍,阿里云决定放弃此前的混合思考模式,转而分别训练 Instruct(指令型)与 Thinking(思考型)模型,以实现更优的模型表现。
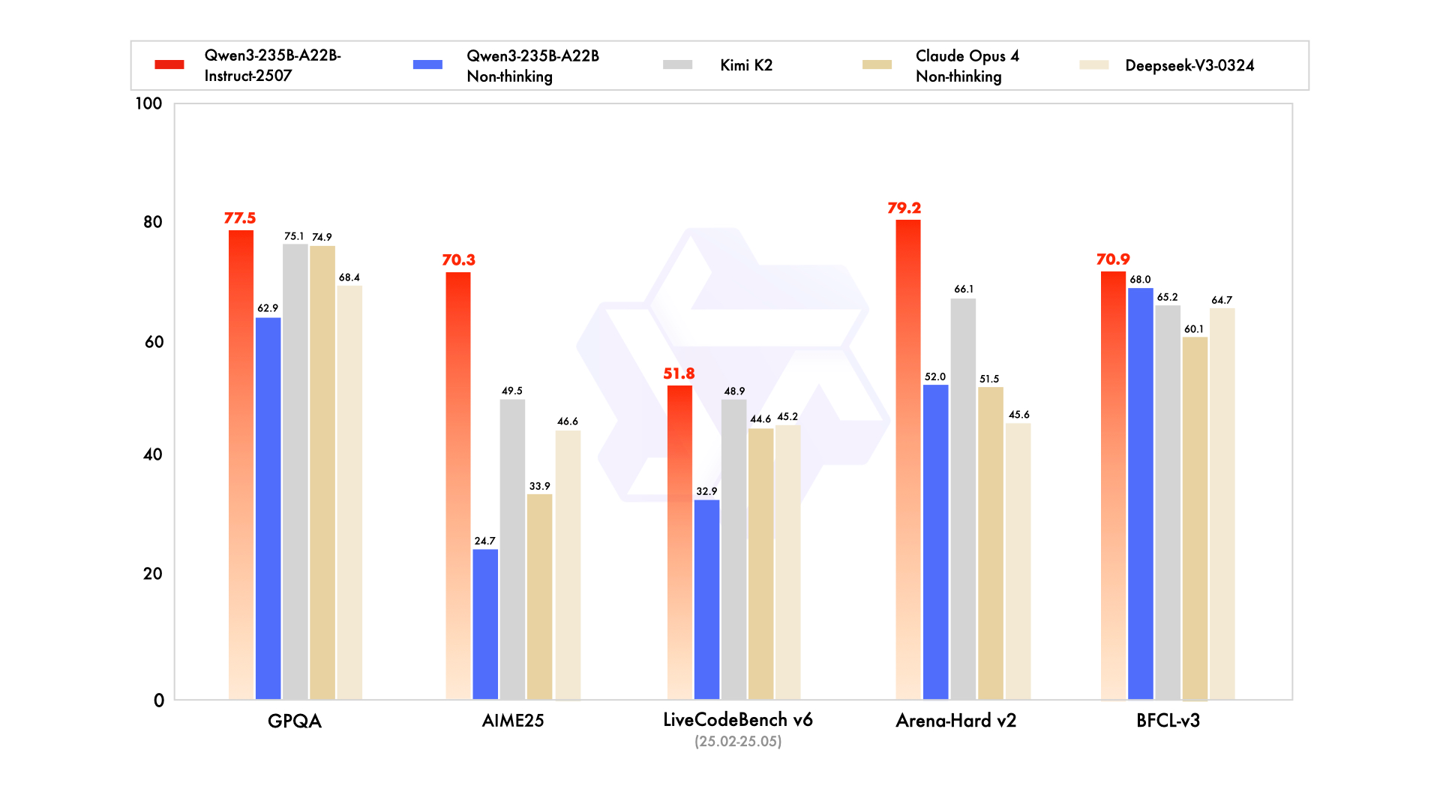
在性能方面,新版本 Qwen3 展现出全方位的能力提升,涵盖指令遵循、逻辑推理、文本理解、数学运算、科学分析、编程能力以及工具使用等多个维度。根据官方公布的数据,该模型在多个权威评测中表现优异,例如 GQPA(知识理解)、AIME25(数学解题)、LiveCodeBench(代码生成)、Arena-Hard(用户偏好对齐)、BFCL(Agent 智能体能力)等榜单中均超越了包括 Kimi-K2、DeepSeek-V3 以及 Claude-Opus4-Non-thinking 在内的多个知名模型。
从技术参数来看,Qwen3-235B-A22B-Instruct-2507-FP8 是一个因果语言模型(自回归模型),其总参数量达到 235B,激活参数为 22B,非嵌入参数量为 234B。模型结构方面,其层数为 94,采用 GQA 注意力机制,Q 头数为 64,KV 头数为 4,专家数量为 128,每次激活 8 个专家。此外,该版本支持高达 262,144 的上下文长度,显著提升了长文本处理能力。
在实际应用层面,Qwen3 还在多个关键领域进行了优化。例如,在多语言支持和长尾知识覆盖方面有了显著提升;在面对主观性和开放性任务时,模型能更好地理解用户意图,提供更贴合需求的高质量回复。同时,其上下文处理能力也进一步增强,长文本支持上限提升至 256K,为复杂任务提供了更强大的支撑。
目前,用户已可通过魔搭社区(ModelScope)和 HuggingFace 平台下载或在线体验该模型。阿里云此次开源举措,无疑将进一步推动大模型技术在开发者社区的普及与应用。
官方资源链接如下:
– 官网地址:https://chat.qwen.ai/
– HuggingFace 地址:https://huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507-FP8
– 魔搭社区地址:https://modelscope.cn/models/Qwen/Qwen3-235B-A22B-Instruct-2507-FP8
Qwen3大模型,阿里云AI,指令型模型,上下文处理,开源大模型
本文来源: IT之家【阅读原文】
IT之家【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号