
编程竞赛新标杆:谢赛宁带领华人团队打造每日更新题目的LiveCodeBench Pro,杜绝刷题,大型语言模型全员挑战零分记录
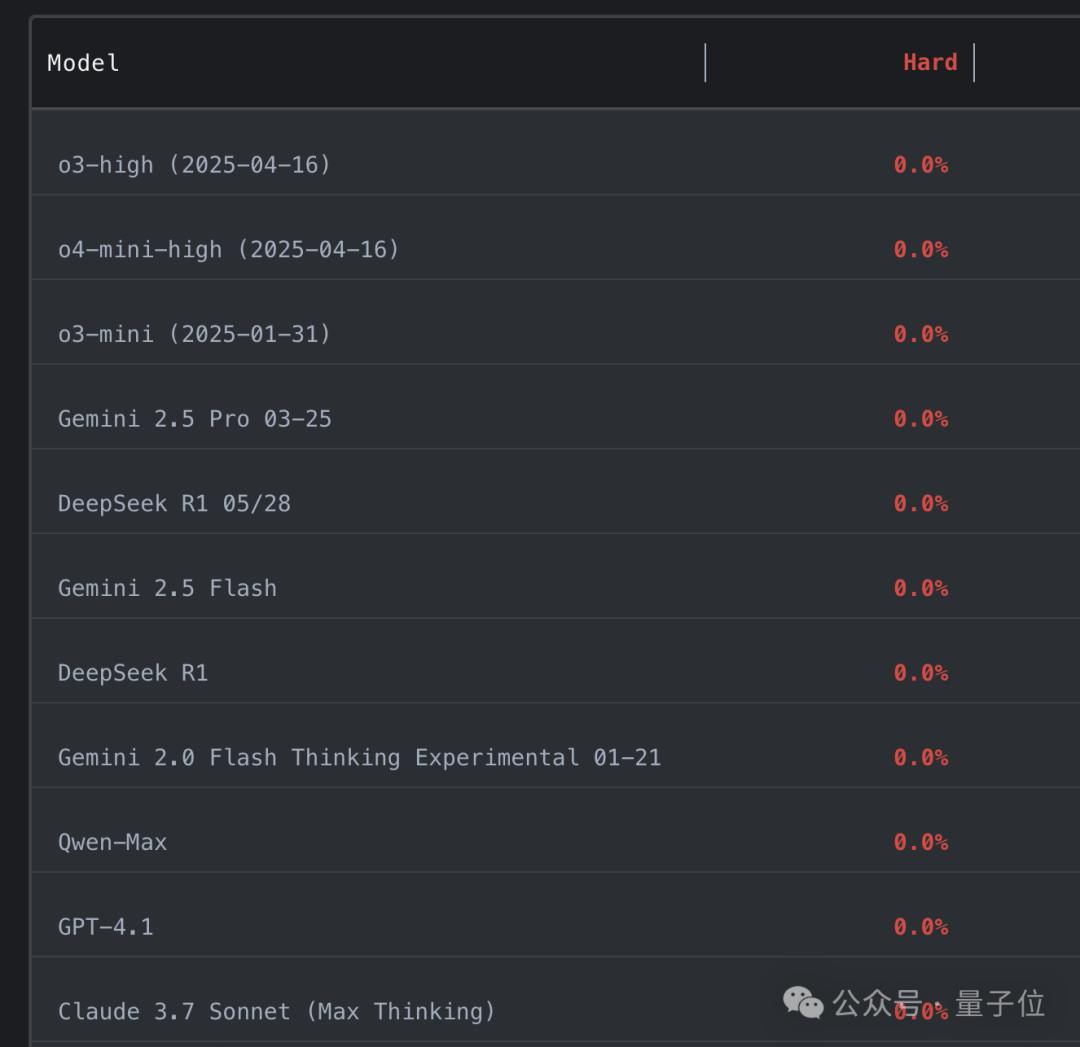
大模型在编程竞赛基准测试中全军覆没,所有参赛模型均获得0分。这一结果由谢赛宁领衔的华人团队发布,其最新推出的LiveCodeBench Pro基准测试引发了广泛关注。该基准测试每日更新题目,旨在防止大型语言模型(LLMs)通过“背题”来提高成绩。
LiveCodeBench Pro包含来自国际信息学奥林匹克竞赛(IOI)、Codeforces和国际大学生程序设计竞赛(ICPC)的高难度编程问题。这些题目覆盖了知识密集型、逻辑密集型和观察密集型三大类,并分为简单、中等和困难三个难度级别。为了确保评估的真实性和挑战性,团队每天都会更新题库,以减少数据污染。
谢赛宁虽然参与了这项工作,但他谦虚地表示自己只是个支持者。此前有报道称,LLM编程能力已超越人类专家,但本次测试结果表明并非如此。表现最佳的模型在中等难度题上的一次通过率仅为53%,而在难题上的通过率为0%。
即使是最优秀的模型o4-mini-high,一旦工具调用被屏蔽,其Elo评分也只有2100,远低于真正大师级的2700传奇线。谢赛宁指出,击败这个基准就像AlphaGo击败李世石一样,目前还没有达到那个水平。
LiveCodeBench Pro不仅是一个动态题库,还深入考验了LLMs的算法逻辑深度。测试结果显示,模型在知识密集型和逻辑密集型问题上表现较好,但在需要创新思维的观察密集型问题上表现较差。与人类相比,LLMs在精确实现方面表现出色,但在算法设计方面逊色。
研究团队由一众奥林匹克竞赛得奖者组成,其中超半数成员为华人。主要负责人郑子涵毕业于成都外国语学校,现就读于纽约大学,曾代表纽约大学参加ICPC世界总决赛并获得第二名。另一位负责人柴文浩毕业于浙江大学,硕士就读于华盛顿大学,今年9月将前往普林斯顿大学攻读博士学位。
项目地址:https://github.com/GavinZhengOI/LiveCodeBench-Pro
排行榜:https://livecodebenchpro.com/
 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号