
标题:DeepSeek开源AI数据处理神器结合3FS分布式文件系统,实现6.6TiB/s惊人吞吐,轻松扩展至PB级数据,助力Smallpond高效运算
深度解析:DeepSeek开源项目3FS和Smallpond为AI数据处理树立新标杆
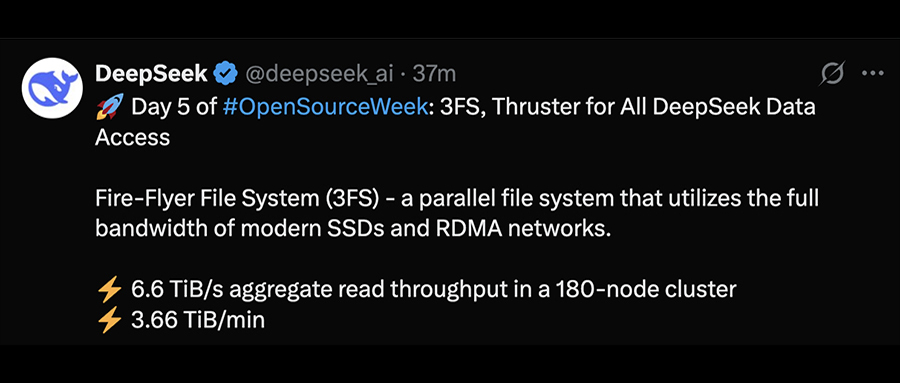
2月28日,智东西报道,DeepSeek发布了其开源周的第五个项目——Fire-Flyer文件系统(3FS)。这个并行文件系统充分利用了现代SSD和RDMA网络的优势,旨在为所有人提供高效的Thruster DeepSeek数据访问。
性能亮点
– 超高吞吐量:在180节点集群中实现了6.6 TiB/s的总读取吞吐量。
– 高效排序:在25节点集群中,GraySort基准测试的吞吐量达到3.66 TiB/min。
– 快速KVCache查找:每个客户端节点的峰值吞吐量高达40+ GiB/s。
架构特点
– 强一致性语义:采用分解式架构,结合了数千个SSD的带宽和数百个存储节点的网络资源,确保应用程序可以无缝访问存储资源。
– 无状态元数据服务:基于事务键值存储(如FoundationDB),提供简单易用的文件接口,无需学习新的API。
多样化工作负载支持
– 数据准备:将数据分析管道的输出组织成分层目录结构,有效管理大量中间输出。
– 数据加载器:通过跨计算节点随机访问训练样本,消除了预取或混洗数据集的需求。
– 检查点支持:实现大规模训练的高吞吐量并行检查点。
– KVCache优化推理:提供一种基于DRAM的缓存替代方案,兼具高吞吐量和大容量。
实际表现
– 峰值吞吐量:一个由180个存储节点组成的大型3FS集群,在约500个客户端节点的压力测试下,最终聚合读吞吐量达到了6.6 TiB/s。
– 灰度排序:通过对8192个分区中的110.5 TiB数据进行排序,耗时30分14秒,平均吞吐量为3.66 TiB/分钟。
– KVCache性能:所有KVCache客户端的读取吞吐量峰值高达40 GiB/s,展示了其卓越的性能。
Smallpond框架
Smallpond是一个基于DuckDB和3FS的轻量级数据处理框架,具备以下特色:
– 高性能数据处理:由DuckDB提供支持,确保高效的数据处理能力。
– 可扩展性:能够处理PB级别的数据集。
– 操作简便:无需长时间运行的服务,简化了操作流程。
评论区用户对3FS的速度赞不绝口,认为它为AI数据处理树立了新标杆。同时,网友们也期待更多更新,如视频模型、V4和R2版本。
本文来源: 智东西【阅读原文】
智东西【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号