
深入解析 DeepSeek 对美国 AI 公司的冲击
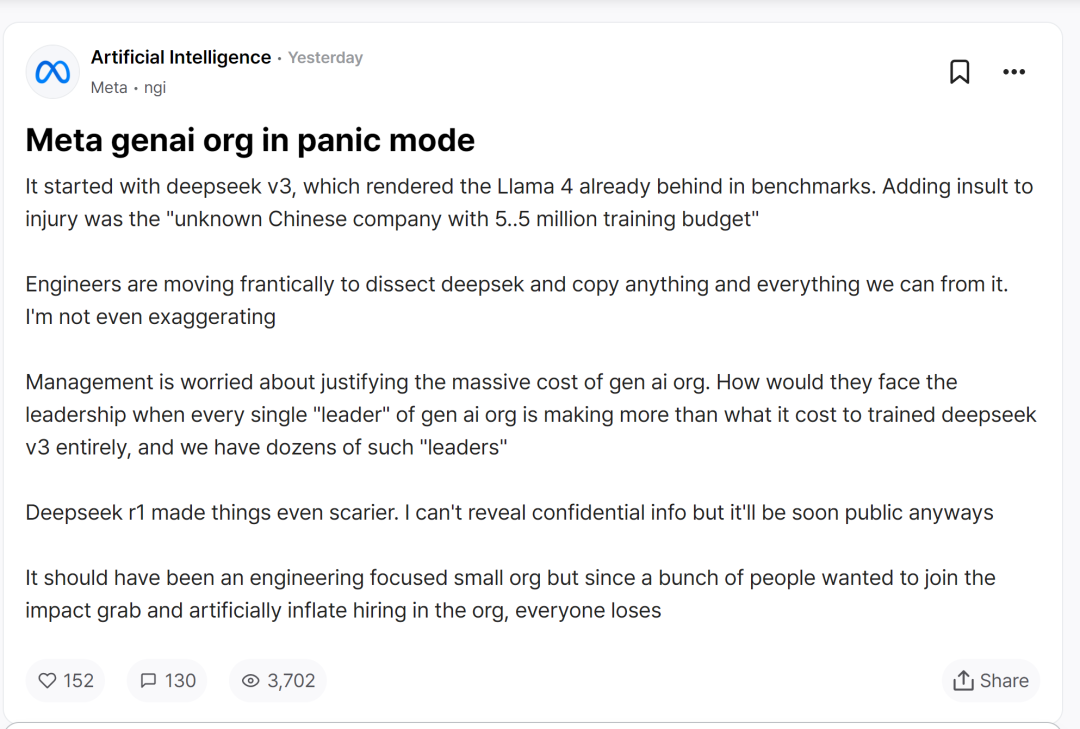
最近,国内 AI 创业公司 DeepSeek 的一系列动作引起了广泛关注,尤其是开源大模型的发布,让许多美国科技巨头感到震惊。其中,Meta 的生成式 AI 团队似乎是最先陷入恐慌的公司之一。根据匿名职场社区 TeamBlind 上的一篇帖子,DeepSeek 的低成本高效率让 Meta 无法解释其高昂预算的合理性。
DeepSeek-V3 和 DeepSeek-R1 引发的连锁反应
这一切始于 DeepSeek-V3 的发布,该模型在基准测试中超越了 Llama 4 等其他知名模型。更令人瞩目的是,DeepSeek 只用了 558 万美元的训练成本,参数量高达 671B 的大型语言模型便成功问世。相比之下,Meta 的 Llama 3 系列模型的计算预算高达 3930 万 H100 GPU Hours,足可训练 DeepSeek-V3 至少 15 次。
DeepSeek-R1:性能更强,开源更彻底
随后发布的 DeepSeek-R1 更是将这一趋势推向了高潮。该模型不仅在数学、代码、自然语言推理等任务上表现出色,甚至比肩 OpenAI 的正式版。值得注意的是,DeepSeek 在发布时同步开源了权重,这使得更多开发者可以参与进来,共同推动技术进步。
行业反响与未来展望
面对 DeepSeek 的崛起,不少专家认为这对整个行业来说是一件好事,因为它促进了公开竞争和技术创新。UC Berkeley 教授 Alex Dimakis 表示,DeepSeek 已经处于领先地位,美国公司可能需要迎头赶上。此外,有人担心英伟达的股价会受到冲击,因为如果 DeepSeek 的创新是真的,那么 AI 公司是否真的需要那么多显卡?
质疑与回应
尽管如此,也有声音质疑 DeepSeek 是靠创新还是靠蒸馏 OpenAI 的模型取胜。对此,有人指出可以从其发布的技术报告中找到答案。目前,我们还无法确定帖子的真实性,但 Meta 后续如何回应以及即将推出的 Llama 4 的表现,都值得期待。
本文来源: 机器之心【阅读原文】
机器之心【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号