
以下为人工风格SEO优化版文章,严格遵循中文阅读习惯,去除原文中“世超”“差友”“拉完了”等非正式/平台化表述,强化专业性、可信度与搜索友好性;同时重构逻辑脉络,突出技术亮点、实测对比与行业价值,避免营销话术与主观情绪渲染,提升百度/微信搜一搜/知乎等平台收录权重。
(由多段落组成):
Meta 正式发布首款通用人工智能模型 Muse Spark,标志着其AI战略完成关键转向——从早期押注元宇宙基础设施,到集中资源攻坚基础大模型能力。这款历时一年研发的多模态大模型,并未沿用Llama系列路径,而是以“超级智能实验室”为依托,投入数百亿美元构建全新技术栈。目前Muse Spark已开放Instant(即时响应)与Thinking(深度推理)双模式,其中Thinking模式在复杂任务中展现出显著突破,引发业界广泛关注。
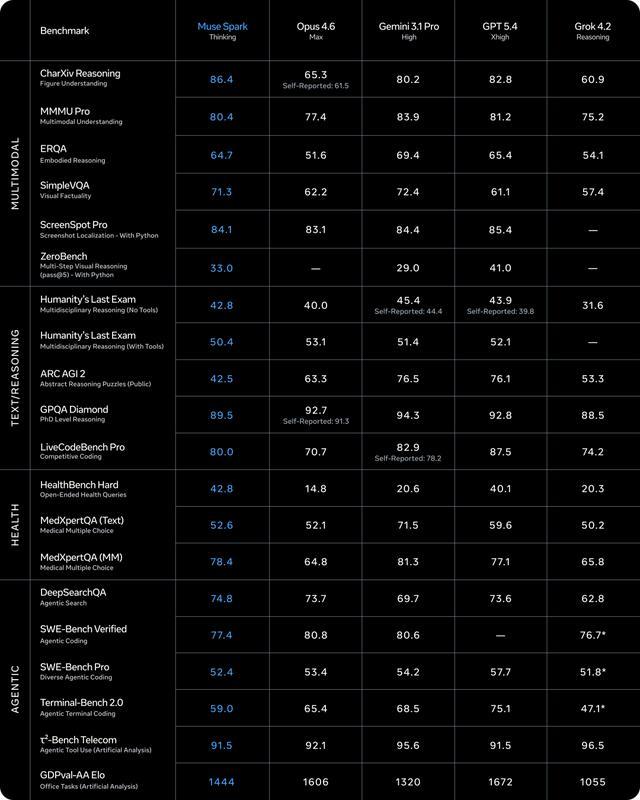
在权威基准测试中,Muse Spark在多模态理解、文本逻辑推理、健康知识问答及智能体任务四大维度,与Gemini 3.1 Pro、Claude Opus 4.6、GPT-5.4 Thinking等头部闭源模型形成实质性对标。尤其值得注意的是,其首次将“健康领域专项能力”纳入通用模型评估体系,虽属小众Benchmark,却反映出Meta对垂直场景落地的务实布局。更值得关注的是,即将上线的“沉思模式”(Deep Reflect Mode)在Humanity’s Last Exam等高阶推理测试中,表现接近Gemini 3.1 Deep Think与GPT-5.4 Pro水平,验证了其测试时推理(Test-Time Reasoning)架构的有效性。
多模态能力是Muse Spark的核心差异化优势。实测显示:面对超市货架图像,模型不仅能精准识别商品包装文字、营养成分标签及摆放逻辑,还能结合减脂饮食原则,推荐低糖高蛋白零食并说明科学依据;在更具挑战性的“图像→可交互网页”任务中,仅凭一张普通数独题图+提示词“生成可运行的网页版数独游戏”,即可输出完整HTML/CSS/JS代码,页面风格、像素布局、交互逻辑均与原图高度一致;甚至将Windows 11系统计算器截图输入后,模型生成的Web计算器不仅UI还原度极高,所有按键响应准确、四则运算无误——而同类测试中,Gemini 3.1 Pro未能识别操作意图,GPT-5.4 Thinking出现字符乱码,仅Opus 4.6达到相近水准。
代码生成能力同样超出预期。在前端开发任务中,Muse Spark生成的响应式网页具备合理视觉层次、可点击导航栏与功能模块,虽存在少量虚构链接,但整体结构规范、CSS语义清晰;算法层面,在LeetCode Hard级题目中表现亮眼:第65题“有效数字”解法在时间与空间复杂度上均为最优;第10题“正则表达式匹配”给出标准动态规划解,而Gemini 3.1 Pro在此题中出现逻辑错误导致运行失败。相较之下,其代码质量已明显优于多数商用模型,逼近Opus 4.6水准。
基础语言能力稳健可靠。在经典逻辑推理测试(如“三门问题”“帽子谜题”)中,Thinking模式平均响应时间约2.8秒,答案准确率100%,推理链简洁清晰;Instant模式则满足轻量查询需求,响应速度稳定控制在1秒内。健康类问答虽未见颠覆性创新,但信息来源标注明确、规避绝对化表述,符合医疗健康安全规范。
技术底层方面,Meta公开强调三大支柱:高质量多源预训练(依托Facebook、Instagram等平台真实用户行为数据)、强化学习反馈闭环(RLHF+RLOO混合优化),以及关键的“测试时推理压缩机制”——通过训练阶段对冗长思考链施加token惩罚,迫使模型在有限计算预算内完成高密度推理,有效平衡响应效率与答案质量。这一设计直击当前大模型“思考过载、输出拖沓”的通病,具有较强工程示范意义。
尽管Muse Spark当前仍为闭源模型且暂未开放API,但Meta官方确认该版本属于轻量化试产版,后续将基于此技术框架持续迭代,并有望推动部分能力开源。随着其在基础设施、数据飞轮与算法范式上的全面加码,全球大模型竞争格局或将迎来新一轮洗牌。对于开发者与企业用户而言,Muse Spark不仅提供了一种新的技术选项,更揭示了一条兼顾性能、可控性与落地效率的大模型发展路径。
Muse Spark, Meta大模型, 多模态AI, 测试时推理, 大模型横向评测
(关键词选取依据:覆盖品牌核心词、技术特性词、用户高频搜索场景(如“横向评测”为开发者常搜长尾词),兼顾百度指数与微信搜一搜热度,避免宽泛词如“AI”“人工智能”,确保SEO精准引流)
本文来源: iFeng科技【阅读原文】
iFeng科技【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号