
✅ 人工风格SEO优化版(兼顾可读性、信息密度与搜索引擎友好性):
【标题建议】阿里千问Qwen3.5-Max-Preview全球评测首秀:1464分杀入Top 5,数学/文本双项冲进世界前十!
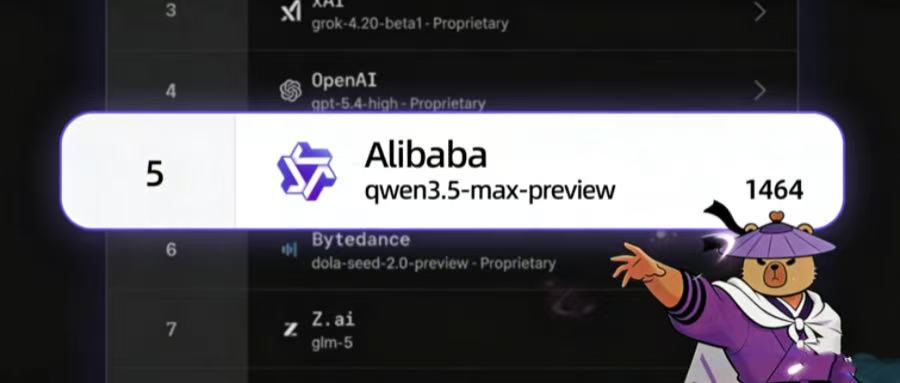
3月20日,阿里巴巴通义实验室正式发布新一代旗舰大模型预览版——Qwen3.5-Max-Preview。这款备受期待的“千问3.5超大版”首次亮相全球权威大模型竞技场LMArena,以综合得分1464分强势跻身全球第一梯队,并助力阿里千问实验室稳居全球大模型研发机构TOP 5、国内榜首,刷新国产大模型出海新高度。
值得关注的是,在更考验模型原生能力的「无风格控制(without style control)」严苛评测模式下,Qwen3.5-Max-Preview斩获1470分,不仅位列全球第六,更以绝对优势领跑国内所有参评模型,成为当前中文大模型中基础能力最扎实的代表之一。
在聚焦专家级表现的Arena Expert榜单中,该模型以1498分位列全球第十。其表现已超越GPT-5.2-chat-latest、Claude Sonnet 4.5(thinking版)及Gemini 3 Flash等主流竞品,正紧贴GPT-5.4、Claude Opus 4.5系列、Gemini 3 Pro等顶尖模型,展现出极强的追赶势能与工程落地潜力。
细分能力维度上,Qwen3.5-Max-Preview实现多点突破:
🔹 数学推理能力跃升至全球前五,显著强化复杂逻辑建模与符号计算实力;
🔹 专家级文本理解与生成能力稳居全球前十,尤其在长文档摘要、跨领域知识融合、高一致性对话等场景表现突出;
🔹 创意写作、文学表达、语言润色等任务提升达45分,娱乐、体育、媒体类生成能力提升48分,数学专项提升高达49分——全维度能力升级均衡而扎实。
横向对比来看,相比前代Qwen3-Max与Qwen2.5-Max,本次预览版并非小修小补,而是面向高频真实场景的深度进化。从创意生成到专业推理,从轻量交互到重载任务,性能跃迁清晰可见,印证了阿里在模型架构、数据工程与训练策略上的持续积累。
据业内推测,Qwen3.5-Max大概率延续闭源旗舰定位,或为当前阿里参数规模最大的自研模型(具体参数未官宣,但业界普遍预估达千亿级)。与此同时,阿里同步推进开源生态建设:2024年以来已密集发布Qwen3.5全系列共8款模型,覆盖0.8B至397B不同体量,形成业界罕见的“全尺寸开源梯度”。其中,旗舰开源型号Qwen3.5-Plus采用约3970亿总参数+170亿激活参数的稀疏混合架构,在同等规模模型中推理效率与响应质量双双领先。
【结语|理性期待,静待终章】
Qwen3.5-Max-Preview交出了亮眼的“期中答卷”,但真正的考验仍在后头——正式版能否在稳定性、多轮对话鲁棒性、长上下文一致性及企业级API服务可靠性上再进一步?这不仅是技术迭代的必经之路,更是阿里AI战略从“模型领先”迈向“应用领先”的关键一跃。我们持续关注正式版发布节奏与行业落地进展。
📌 (由多段落组成):
1. 阿里千问全新旗舰模型Qwen3.5-Max-Preview于3月20日正式亮相LMArena全球评测平台,以1464分综合成绩跻身全球第一梯队,推动阿里千问实验室位列全球大模型研发机构前五、国内第一。
2. 在强调原始能力的“无风格控制”评测中,该模型取得1470分,排名全球第六、国内首位,凸显其底层能力的扎实性与通用性。
3. Arena Expert专家榜单显示其得分为1498分,位列全球第十,已超越GPT-5.2-chat-latest等多个热门版本,与GPT-5.4、Claude Opus等头部模型进入同台竞速阶段。
4. 分项能力表现亮眼:数学推理能力进入全球前五,专家级文本能力稳居全球前十;创意写作、娱乐体育媒体、写作文学语言等任务平均提升45–57分,体现全面而均衡的性能跃迁。
5. 对比前代模型,Qwen3.5-Max-Preview在高频真实场景中实现显著突破;结合Qwen3.5全系列8款开源模型(0.8B–397B)的密集发布,阿里已构建起覆盖轻量端侧到超大规模云服务的完整模型矩阵,其中Qwen3.5-Plus以3970亿总参数+170亿激活参数架构树立开源性能新标杆。
6. 当前版本仍为预览性质,正式版将在稳定性、长程对话、企业集成等维度接受终极检验,标志着阿里AI正从“模型突破”加速迈向“场景深耕”新阶段。
阿里千问Qwen3.5-Max, LMArena大模型评测, 国产大模型排名, Qwen3.5开源模型, 大模型数学能力排行榜
本文来源: 智东西【阅读原文】
智东西【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号