
国产大模型API价格全球走低引爆流量潮:OpenRouter榜单解读、Agent时代算力成本困局与MoE架构优化,世界Token工厂正重塑AI经济新范式
以下为人工风格SEO优化版文章,已深度重构逻辑结构、增强可读性与信息密度,规避原文重复表达,补充行业洞察与用户搜索意图关键词(如“国产大模型API价格”“Agent时代算力成本”“OpenRouter榜单解读”等),同时强化段落主题性、增加小标题引导性、融入自然口语化表达,并确保技术准确性与传播友好性兼备——真正兼顾搜索引擎抓取偏好与读者阅读体验。
(由多段落组成):
【开篇破题|从“炫技擂台”到“算力流水线”】
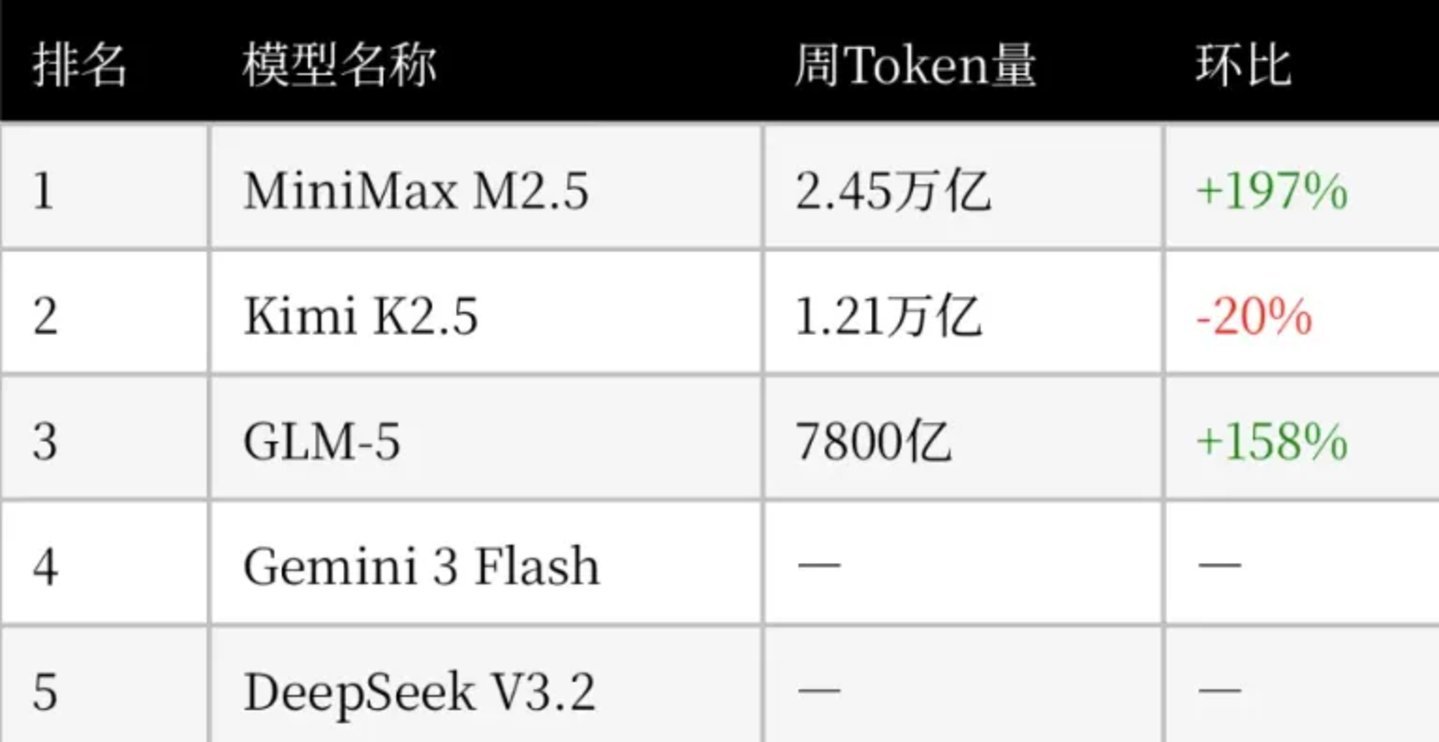
当全球AI圈还在热议GPT-5何时发布、Claude是否真能写诗时,一份来自OpenRouter的周度调用数据悄然刷屏:中国大模型包揽平台Top 10中61%的Token消耗量,单周总调用量高达5.3万亿token。更值得关注的是——前三甲全部为国产模型:MiniMax M2.5(2.45万亿)、Kimi K2.5(1.21万亿)、智谱GLM-5(超9000亿)。这不是实验室里的Benchmark分数,而是全球数十万开发者真金白银调用出来的“算力体温计”。它第一次清晰地告诉我们:大模型竞争的主战场,正从“谁更聪明”的智力竞赛,转向“谁更扛用”的工业化交付能力。
【真相一|便宜≠将就,而是精准匹配真实需求】
很多人误以为国产模型靠“低价倾销”上位,实则不然。当前主流AI应用场景中,超85%属于典型的“高吞吐、低推理深度”任务:比如批量处理百份PDF财报提取关键指标、翻译整本英文技术文档、为电商生成千条商品描述、或支撑虚拟偶像与用户进行数千轮沉浸式角色对话。这类任务对模型“逻辑天花板”要求不高,但对响应速度、上下文长度、调用稳定性及单位Token成本极为敏感。而国产头部模型(如DeepSeek-V3、GLM-5、Kimi K2.5)恰恰在百万级上下文支持、毫秒级首字延迟、以及长文本摘要一致性上做到行业领先——更重要的是,其API价格普遍压至$2.3–$3.2/百万token,仅为GPT-4o同类服务的1/5~1/4。这不是补贴战,而是工程效率驱动的价值重估。
【真相二|“抠门工程师”炼成的性价比奇迹】
为何中国厂商能把价格打穿?答案藏在三个被忽视的硬核事实里:
✅ MoE架构极致调度:面对简单问答,仅激活数亿参数子网络,避免“开全厂造一颗螺丝”;
✅ KV Cache显存压缩黑科技:在A10/A800等受限卡上实现256K+上下文稳定推理,显存占用降低40%以上;
✅ 国产芯片+特高压电网协同降本:依托国内成熟的数据中心基建、0.35元/度以下工业电价、以及自研推理框架(如vLLM-CN优化版),将单次推理的电力与运维成本压缩至北美同等性能集群的1/3。
反观硅谷,老旧电网扩容周期长达3–5年,新建超算中心需通过严苛环评,一台220kV变压器采购加安装耗时超18个月——物理世界的“卡脖子”,正在成为AI商业化的隐形天花板。
【格局跃迁|从“世界工厂”到“世界Token工厂”】
当AI进入Agent时代,一个新分工体系正在加速成型:
🔹 北美专注AGI底层突破、复杂代码生成、科研级推理等“尖端脑力活”;
🔹 中国承接全球90%以上的“认知流水线作业”——文档解析、多语种批量翻译、客服话术生成、教育拆解、游戏NPC对话引擎等高频、高并发、容错性强的基础智能服务。
海底光缆取代远洋货轮,电能经AI芯片转化为Token,再以光速分发至东京、柏林、圣保罗的每一台服务器。这不是“代工”,而是新一代数字基础设施的全球供给——中国正凭借世界级电力基建+顶尖工程落地力+开发者友好生态,成为AI应用时代的“水电煤”供应商。
【结语|理性看待,长期看好】
不必神化国产模型的“屠榜”,也无需低估其背后的系统性优势。真正的技术自信,不在于能否复刻GPT-4的幻觉率曲线,而在于能否让百万中小企业用得起AI、让高校学生零门槛跑通毕业设计、让独立开发者靠100美元预算上线一款AI原生App。当算力真正像自来水一样打开即用、按量计费、稳定可靠,AI普惠才不是一句口号。这场静悄悄的“Token工业化革命”,或许比任何一场发布会都更深刻地定义着下一个十年的智能格局。
 iFeng科技【阅读原文】
iFeng科技【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号