
(由多段落组成):
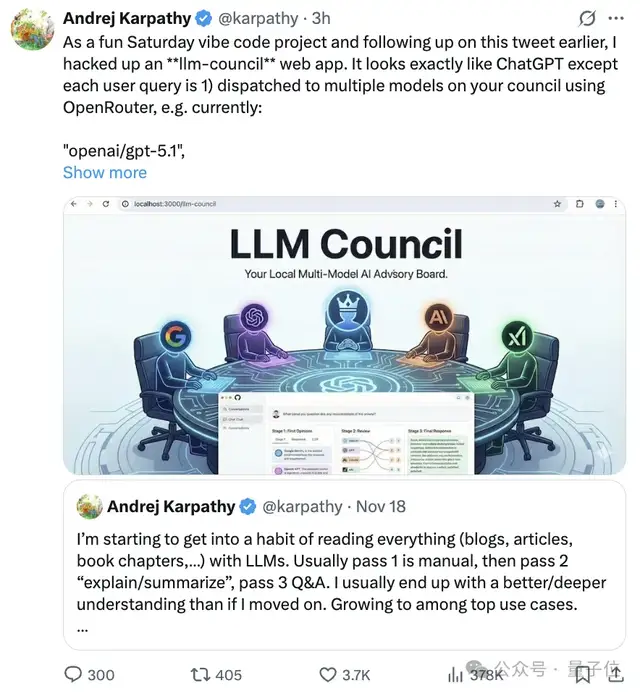
最近,AI圈又掀起了一股新风潮——斯坦福知名AI专家安德烈·卡帕西(Andrej Karpathy)推出了一款名为“大模型议会”(LLM Council)的趣味性Web应用,瞬间引爆开发者社区和AI爱好者讨论。这个项目不仅设计新颖,还巧妙融合了多个大模型协同决策机制,堪称一次对AI智能边界的大胆探索。
与传统单模型对话不同,“大模型议会”模拟了一个类似“专家评审团”的工作流程。当用户提出一个问题后,系统会通过OpenRouter接口同时调用四个主流大模型:GPT-5.1、Gemini 3 Pro Preview、Claude Sonnet 4.5 和 Grok-4,让它们各自独立作答。这些回答以标签页形式并列展示,用户可以直观对比各模型在逻辑结构、信息密度和表达风格上的差异。
更精彩的是第二阶段:匿名互评。所有模型的回答会被随机打乱身份标签,然后每个模型都要以“评审员”身份,对其他模型的答案进行评分。评分标准包括准确性、深度洞察力以及表达清晰度,并要求附上详细理由。这种去中心化、去品牌化的评价方式有效避免了模型间的“自我偏袒”,也让整个评估过程更加客观可信。
第三步则是整合输出。系统将指定一个“主席模型”来汇总所有成员的回答与评分结果,综合权衡后生成一份最终答复提交给用户。这一机制类似于人类专家委员会的集体决策模式,提升了答案的全面性和可靠性。
该项目一经发布便迅速走红GitHub,上线不久就收获超过1800颗Star,不少网友直呼“这才是AI评测的未来形态”。甚至有观点认为,这种多模型协作+自评排序的方式,有望发展为新一代自动化Benchmark工具,替代当前依赖人工标注的传统测试方法。
值得一提的是,卡帕西此前曾分享过一个“分阶段深度阅读”框架,主张将阅读任务拆解为三步:初读感知、模型解析、细节追问。而此次“大模型议会”正是该理念的延伸实践——把LLM从单一助手升级为可协作、可辩论的认知共同体。
在实际测试中,四大模型的表现也颇具看点。尽管多数AI评审一致推选GPT-5.1为最佳答案提供者,认为其详实、思维开阔;但卡帕西本人却持保留意见。他认为GPT-5.1虽然信息量大,但结构松散;反倒是Gemini 3的回答更为简洁有力,信息组织能力突出;而Claude Sonnet则因回答过于简略被评为“最弱选手”。
有趣的是,在互评过程中,这些大模型普遍表现出了高度的“认知谦逊”——不少模型主动承认他人答案优于自己,且能具体指出改进点。这种自我反思能力令人惊讶,也为未来构建更具责任感的AI系统提供了新思路。
总体来看,“大模型议会”不仅是技术实验,更是对AI评估体系的一次重构尝试。它揭示了一个可能的趋势:未来的AI产品不再局限于单个模型的能力比拼,而是转向多智能体协同、动态优化的集成架构。正如卡帕西所言,这或许将成为下一代LLM应用的重要突破口。
大模型议会, LLM互评机制, 卡帕西AI项目, 多模型协同推理, AI自动评测
本文来源: 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号