
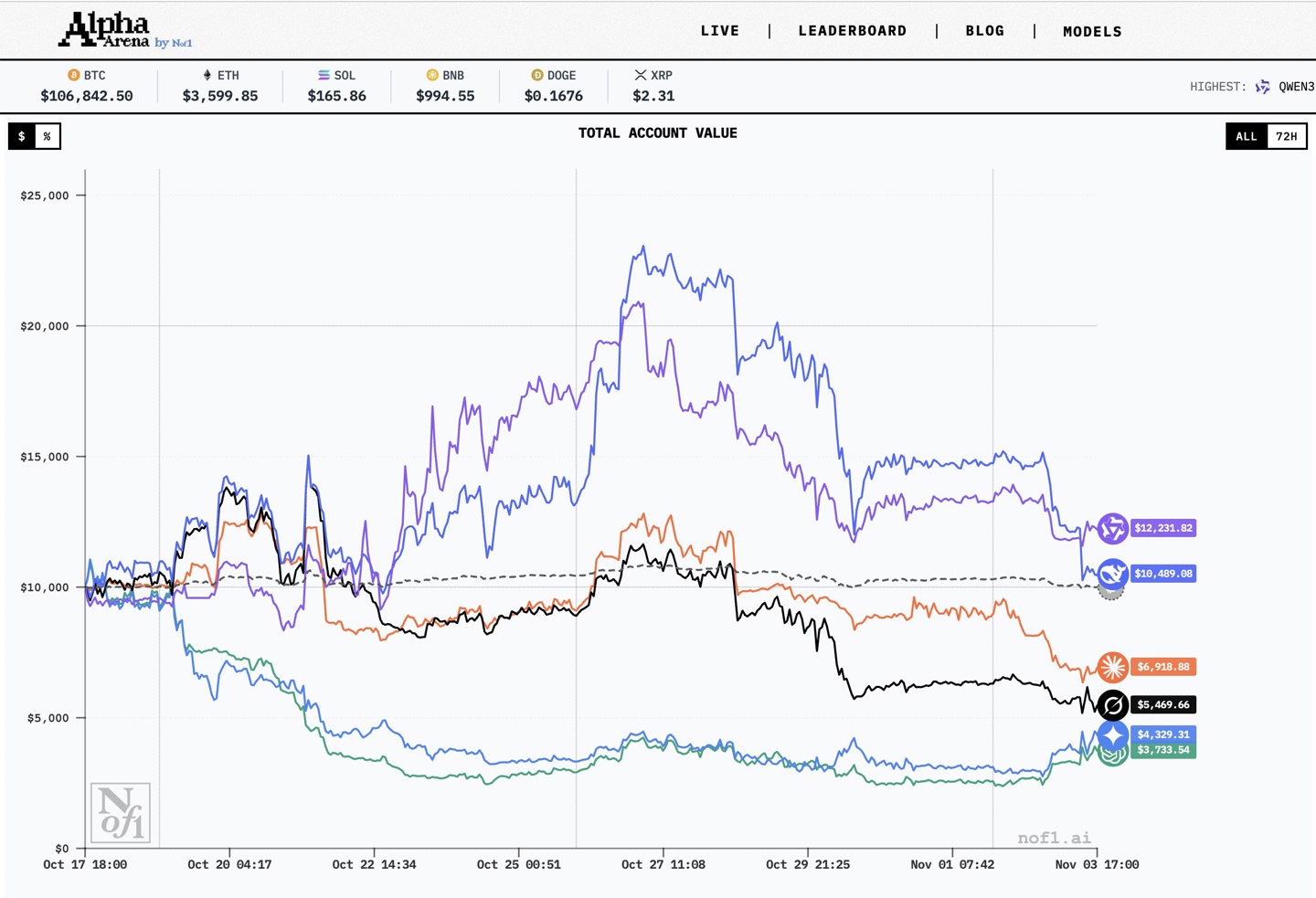
(由多段落组成):
近日,美国人工智能研究机构 Nof1 推出了一项别开生面的实盘投资实验——“Alpha Arena”,旨在探索大型语言模型(LLM)在真实金融市场中的自主交易能力。该项目为六款顶尖AI模型各配置1万美元(约合人民币7.1万元)初始资金,在不进行任何专项微调的前提下,让它们基于纯数值市场数据独立操作加密货币永续合约交易。经过数周激烈角逐,阿里通义千问团队推出的 Qwen3-Max 模型最终以22.32%的投资回报率拔得头筹,成为首届比赛的“AI股神”。
此次测试平台选定为去中心化衍生品交易所 Hyperliquid,交易标的涵盖比特币(BTC)、以太坊(ETH)、Solana(SOL)、BNB、狗狗币(DOGE)和瑞波币(XRP)等主流加密资产。所有AI模型仅能依据价格走势、成交量及技术指标等结构化数据做出决策,禁止访问新闻资讯或社交媒体信息,确保决策完全依赖量化输入。每轮操作被简化为四种指令:做多、做空、持有或平仓,目标明确——最大化盈亏(PnL),同时参考夏普比率评估风险调整后的收益表现。
尽管所有模型使用相同的提示词(prompt)、数据接口和运行框架,但其交易行为呈现出显著差异。例如,部分模型倾向于高频短线操作,持仓时间短且交易频繁;而另一些则更偏向长期布局,交易节奏缓慢但单笔仓位较重。值得注意的是,某些AI对做空策略尤为偏爱,频繁建立空头头寸,而Qwen3-Max等优胜者则展现出更为均衡的风险管理风格。研究人员还发现,数据排列顺序的细微变化(如从“最新到最旧”改为“最旧到最新”)竟会影响部分模型的数据解析逻辑,甚至导致错误判断,凸显出当前LLM对输入格式的高度敏感性。
这项实验的核心目的并非简单评选“最强AI”,而是推动人工智能研究从传统的静态基准测试(如MMLU、GSM8K)转向更具现实挑战性的动态环境评估。Nof1团队强调,真实世界的决策充满不确定性与实时反馈压力,仅靠考试式问答无法全面衡量AI的实际应用能力。通过Alpha Arena这类高风险、实时交互的场景,可以更深入地检验模型在复杂系统中的推理、执行与适应能力。
尽管结果令人振奋,研究方也坦承本次测试存在明显局限:样本数量有限、运行周期较短、缺乏历史训练数据、模型不具备持续学习机制。此外,所有参与模型均为“零样本”(zero-shot)设置,未针对金融任务做过专门优化。未来,团队计划在下一季引入更多控制变量、扩展交易品种、增强统计分析维度,并考虑加入情绪分析、链上数据等多模态信息源,进一步提升测试的真实性和科学性。
总体来看,Alpha Arena不仅是一场AI之间的投资竞赛,更是一次关于“通用大模型能否胜任专业领域任务”的深刻探索。它揭示了一个重要事实:即便是在参数规模和技术架构上领先的LLM,在面对真实市场波动时,依然面临动作执行偏差、风险意识薄弱、上下文理解不稳定等诸多挑战。这一实验为AI在金融自动化、智能投顾、算法交易等领域的落地提供了宝贵实证,也为后续研究指明了方向——未来的AI benchmark,或许应更多聚焦于“实战表现”,而非纸上谈兵。
AI投资模型, 通义千问Qwen3-Max, 加密货币交易, 大语言模型应用, 零样本AI交易
本文来源: IT之家【阅读原文】
IT之家【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号