
微软在LLM(大语言模型)领域的研究再次取得突破,发布了全新的BitNet v2框架。这一框架实现了1 bit LLM的原生4 bit激活值量化,能够充分利用新一代GPU(如GB200)对4 bit计算的支持能力,从而显著减少内存带宽占用并提升计算效率。
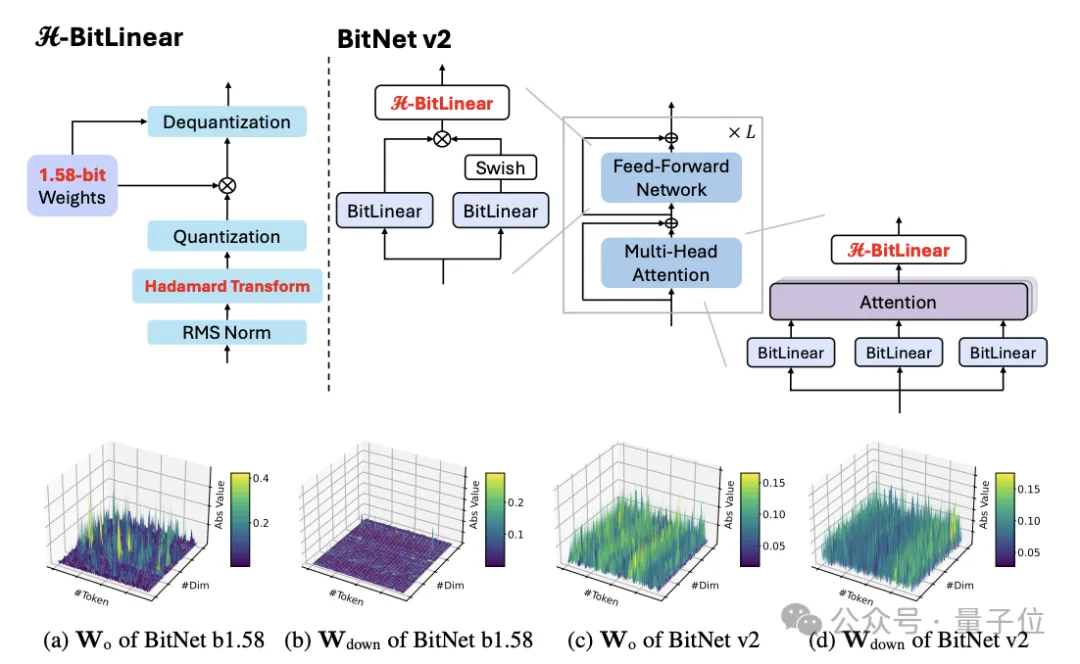
此前,微软曾推出BitNet b1.58框架,将LLM的权重量化至1.58-bit,大幅降低了推理延迟和内存占用等成本。然而,BitNet b1.58的激活值仍为8-bit,无法充分发挥新一代硬件的4 bit计算能力,导致计算环节存在效率瓶颈。此外,研究还发现注意力层和前馈网络层的输入激活值分布接近高斯分布,相对容易量化,但中间状态的激活值存在大量异常值,给低bit量化带来了挑战。
为解决这些问题,微软团队推出了BitNet v2框架,并引入了H-BitLinear模块。该模块在激活量化前应用Hadamard变换,有效重塑了注意力层和前馈网络中尖锐的激活分布,使其更接近高斯分布,显著减少了异常值数量,从而使4 bit激活量化成为可能。
对于权重量化,团队使用per-tensor absmean函数将权重三元量化为{-1, 0, 1}。而对于低bit激活,团队引入了H-BitLinear模块,将其应用于注意力层的权重矩阵Wo和前馈网络(FFN)层的Wdown中。通过Hadamard变换,中间状态分布更接近高斯分布,减少了异常值数量,更适合INT4量化。
在训练策略方面,研究人员采用STE近似梯度,并利用混合精度训练更新参数。在反向传播时,绕过量化中的不可微函数,并利用Hadamard变换矩阵的正交性对梯度进行变换。此外,4 bit激活的BitNet v2可以从8 bit激活版本继续训练,仅需少量数据微调即可忽略性能损失,优化器状态也可继承。
实验结果显示,BitNet v2在不同模型规模(400M、1.3B、3B和7B)上与BitNet b1.58和BitNet a4.8进行了对比。所有模型均使用1.58bit权重训练。结果表明,引入Hadamard变换的BitNet v2(8 bit激活)在各规模模型上的表现优于BitNet b1.58,在7B规模上平均准确率提高了0.61%。当降至4 bit激活时,BitNet v2的困惑度与BitNet a4.8相当,下游任务表现甚至更优。
此外,研究者还对BitNet v2进行了低bit注意力状态的详细实验,采用后RoPE量化处理QKV状态。在3 bit KV缓存的情况下,BitNet v2在3B和7B模型上达到了与全精度KV缓存版本相当的准确率。与后训练量化方法SpinQuant和QuaRot相比,BitNet v2表现更优。消融实验进一步验证了Hadamard变换对低bit激活的关键作用,没有旋转变换则模型会发散。
更多研究细节可参考原论文链接:https://arxiv.org/pdf/2504.18415。
本文来源: 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号