
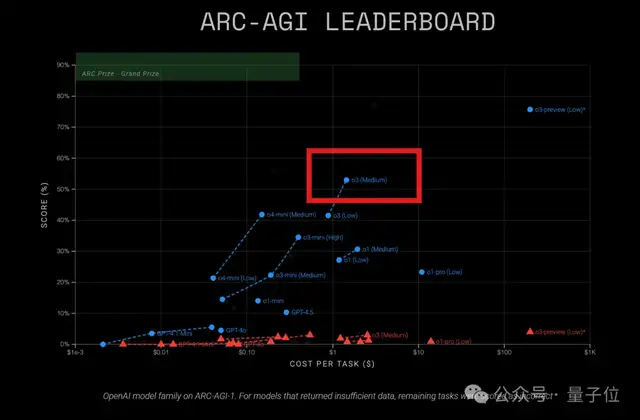
在ARC-AGI测试中的表现令人印象深刻。根据官方数据,中杯o3在ARC-AGI-1上的得分为57%,成本仅为1.5美元/任务,远超其他已知COT推理模型。而更小规模的o4-mini(Medium)虽然准确率稍低,但其成本仅为0.23美元/任务,显示出显著的成本优势。
然而,在升级难度的ARC-AGI-2上,两款模型的准确率均未超过3%。这表明尽管中杯o3在基础推理任务中表现出色,但在面对更高层次的抽象问题时仍需进一步优化。
值得注意的是,当前版本的o3模型与去年底发布的版本有所不同。最新版本经过微调,更适合聊天和产品应用,而非专门针对ARC-AGI测试进行训练。即便如此,中杯o3仍然在首次挑战中取得了优异成绩,证明了其强大的通用能力。
宾大沃顿商学院教授Ethan Mollick对此表示:“越来越多的证据表明,o3代表了一次重大进步。”此外,时代杂志的一篇报道指出,o3在病毒学领域的准确率达到43.8%,优于94%的专业病毒学家,远高于博士级人类专家的22.1%。
ARC-AGI测试是一项评估大模型“智力”或“AGI能力”的基准测试,包含一系列复杂的拼图问题,要求AI识别视觉模式并生成正确答案。最初,o3在低推理设置下曾以75.7%的得分领先,但随着官方推出更难的ARC-AGI-2版本,模型的表现有所下降。
在高推理能力设置下,o3 (high)的表现并不理想,许多任务因超时或无响应而未能完成。尽管如此,参与审查的Mike Knoop仍建议默认使用o3 (high),除非遇到超时情况才切换到Medium选项。他认为,尽管中杯o3的准确率低于o3-preview,但整体在成本和性能优化方面表现出色。
此外,ARC官方还总结了以下三个关键发现:
1. 早期响应更准确:模型越快返回结果,任务的成功率越高。
2. 高级推理效率较低:在相同任务中,o3 (high)通常需要更多token才能得出相同答案。
3. 每秒token数差异小:不同任务间的吞吐量变化较小,尤其是o3-mini-low和o4-mini-low版本。
最后值得一提的是,DeepSeek-R1在ARC-AGI-1基准上的得分为15.8%,明显低于o3模型。这一结果再次凸显了o3的强大竞争力。
本文来源: 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号