
DeepSeek公布推理时Scaling新论文:自我原则批评调整(SPCT)、元奖励模型(meta RM)与强化学习(RL)结合,或预示R2到来,探索推理时间扩展的深远影响。
这可能是 DeepSeek R2 的雏形吗?上周五,DeepSeek 在 arXiv 上提交的一篇最新论文正在 AI 社区内引发热议。目前,强化学习(RL)已被广泛应用于大语言模型(LLM)的后期训练中。最近的研究表明,通过适当的 RL 方法可以显著提升 LLM 的推理能力,从而实现高效的推理时间扩展性。
然而,RL 面临的一个关键挑战是如何在可验证问题或人工规则之外的领域获取准确的奖励信号。上周五提交的一项研究中,来自 DeepSeek 和清华大学的研究人员探索了奖励模型(RM)的不同方法,并发现逐点生成奖励模型(GRM)能够统一纯语言表示中单个、成对和多个响应的评分,从而有效克服这一挑战。
研究人员还探讨了某些原则如何指导 GRM 生成高质量奖励,从而提升奖励的质量。这启发我们可以通过扩展高质量原则和准确批评的生成来实现 RM 的推理时间扩展性。
论文Inference-Time Scaling for Generalist Reward Modeling
论文链接:https://arxiv.org/abs/2504.02495
基于这一初步成果,作者提出了一种新的学习方法——自我原则批评调整(SPCT),以促进 GRM 中有效的推理时间扩展行为。通过基于规则的在线 RL,SPCT 使 GRM 能够根据输入查询和响应自适应地提出原则和批评,从而在更广泛的领域内获得更好的结果。
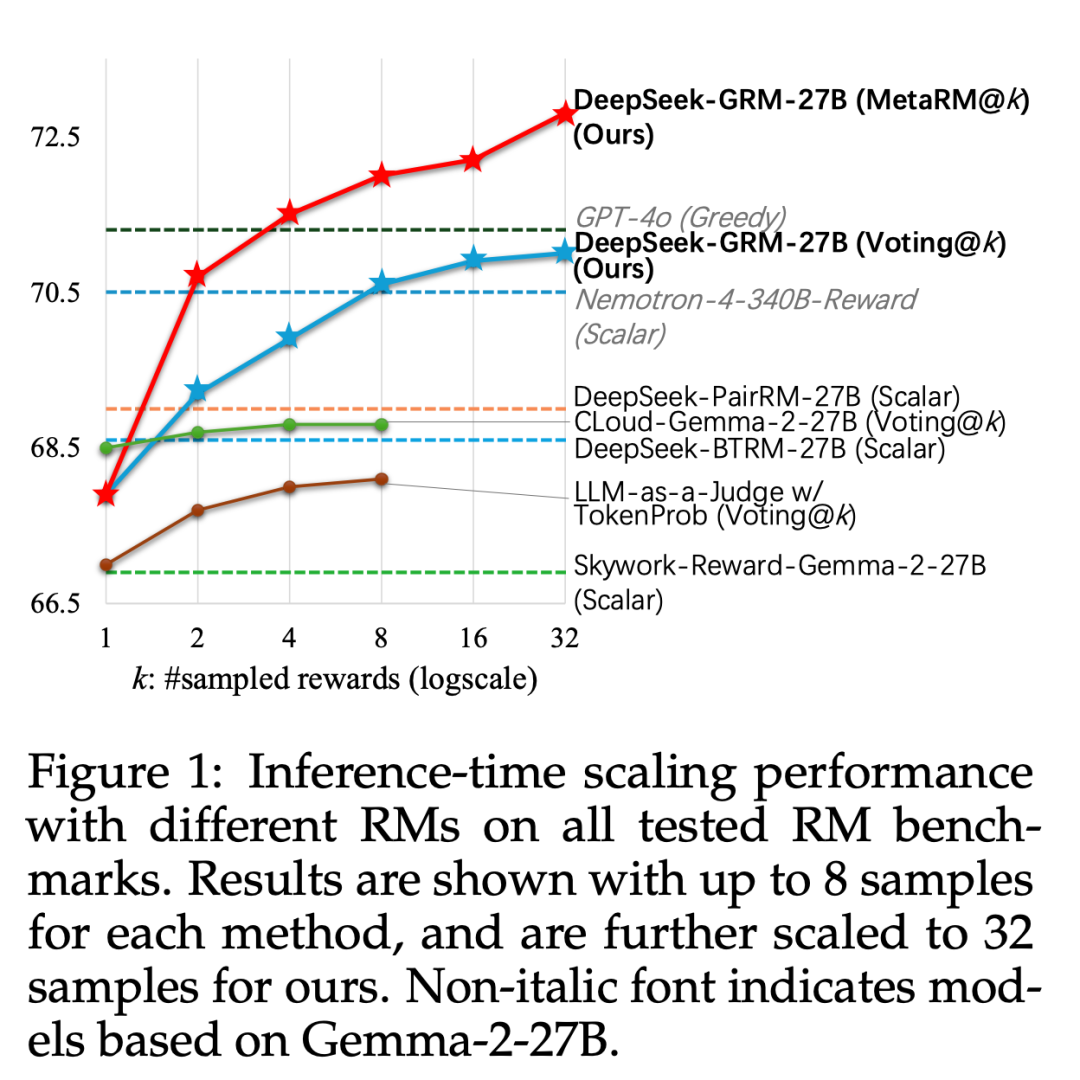
基于此技术,DeepSeek 提出了 DeepSeek-GRM-27B,它基于 Gemma-2-27B 使用 SPCT 进行后训练。对于推理时间扩展,它通过多次采样来扩展计算使用量。通过并行采样,DeepSeek-GRM 可以生成不同的原则集和相应的批评,然后通过投票选出最终的奖励。通过更大规模的采样,DeepSeek-GRM 可以更准确地判断具有更高多样性的原则,并以更细的粒度输出奖励,从而解决挑战。
除了投票以获得更好的扩展性能外,DeepSeek 还训练了一个元 RM。实验结果显示,SPCT 显著提高了 GRM 的质量和可扩展性,在多个综合 RM 基准测试中优于现有方法和模型,且没有严重的领域偏差。此外,作者还将 DeepSeek-GRM-27B 的推理时间扩展性能与多达 671B 参数的较大模型进行了比较,发现其在模型大小上可以获得比训练时间扩展更好的性能。
尽管当前方法在效率和特定任务方面仍面临挑战,但 DeepSeek 相信,通过 SPCT 等努力,具有增强可扩展性和效率的 GRM 可以作为通用奖励系统的多功能接口,推动 LLM 后训练和推理的前沿发展。
这项研究的主要贡献有以下三点:
1. 研究者提出了一种新方法——自我原则批评调整(SPCT),用于提升通用奖励模型在推理阶段的可扩展性,并由此训练出 DeepSeek-GRM 系列模型。
2. 研究者进一步引入了一种元奖励模型(meta RM),使 DeepSeek-GRM 的推理效果在超越传统投票机制的基础上得到进一步提升。
3. 实验证明,SPCT 在生成质量和推理阶段的可扩展性方面明显优于现有方法,并超过了多个强大的开源模型。SPCT 的训练方案还被应用到更大规模的语言模型上。研究者发现推理阶段的扩展性收益甚至超过了通过增加模型规模所带来的训练效果提升。
技术细节部分详细介绍了 SPCT 的设计原理和实现方式。SPCT 包含两个阶段:拒绝式微调(rejective fine-tuning)作为冷启动阶段,以及基于规则的在线强化学习(rule-based online RL),通过不断优化生成的准则和评论,进一步增强泛化型奖励生成能力。此外,SPCT 还能促使奖励模型在推理阶段展现出良好的扩展能力。
本文来源: 机器之心【阅读原文】
机器之心【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号