
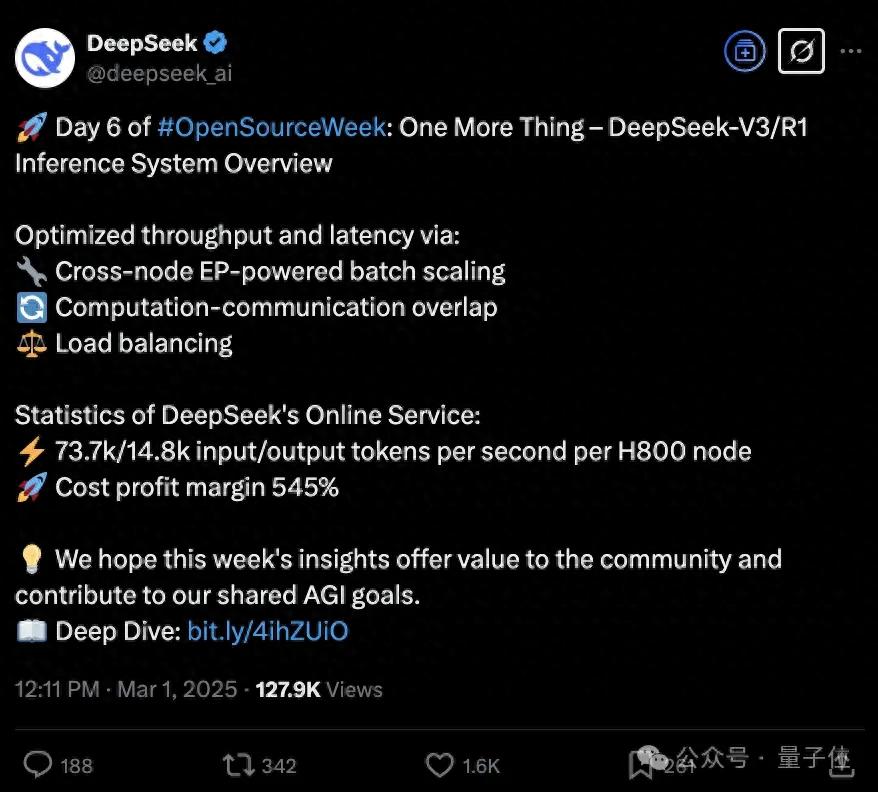
揭秘DeepSeek-V3/R1推理系统:545%成本利润率的背后
近日,DeepSeek官方正式公布了其最新的DeepSeek-V3/R1推理系统的详细信息,并透露了惊人的成本利润率——高达545%。这一消息迅速引发了广泛关注。本文将深入解析DeepSeek-V3/R1的优化技术及其在线服务数据统计。
优化吞吐量与延迟的关键技术
为了实现更高的吞吐量和更低的延迟,DeepSeek-V3/R1采用了大规模跨节点专家并行(Expert Parallelism/EP)技术。以下是具体的技术细节:
1. 跨节点EP驱动的批量扩展:
– EP使得batch size大大增加,从而提高了GPU矩阵乘法的效率。
– 每个GPU仅需计算少量专家,减少了访存需求,降低了延迟。
2. 计算与通信重叠:
– 多机多卡间的专家并行引入了较大的通信开销,通过双batch重叠技术掩盖通信耗时,显著提升了整体吞吐量。
– Prefill阶段:两个batch的计算和通信交错进行,一个batch在计算时可以掩盖另一个batch的通信开销。
– Decode阶段:attention部分被拆分为两个stage,共计五个stage的流水线,实现了计算和通信的重叠。
3. 负载均衡:
– 确保每个GPU的计算和通信负载均衡,避免性能瓶颈。
– Prefill Load Balancer:确保各GPU的core-attention计算量和dispatch发送量尽量相同。
– Decode Load Balancer:保证各GPU的KVCache占用量和请求数量尽量相同。
– Expert-Parallel Load Balancer:最小化所有GPU的dispatch接收量的最大值,使专家计算量均衡。
在线服务数据统计
DeepSeek-V3/R1的所有服务均使用H800 GPU,并采用与训练一致的精度格式,以确保最佳的服务效果。以下是关键的统计数据:
– 输入/输出token速率:每个H800节点每秒处理73.7k/14.8k个输入/输出token。
– 成本利润率:在24小时内,总成本为$87,072/天,总收入理论上可达$562,027,成本利润率高达545%。
– 实际收入情况:考虑到V3定价较低及夜间折扣等因素,实际收入并未达到理论值,但依然表现出色。
结语
DeepSeek-V3/R1推理系统的成功不仅在于其卓越的技术创新,更在于其高效的资源利用和成本控制。未来,DeepSeek将继续优化其技术,为用户提供更加优质的服务。
本文来源: 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号