
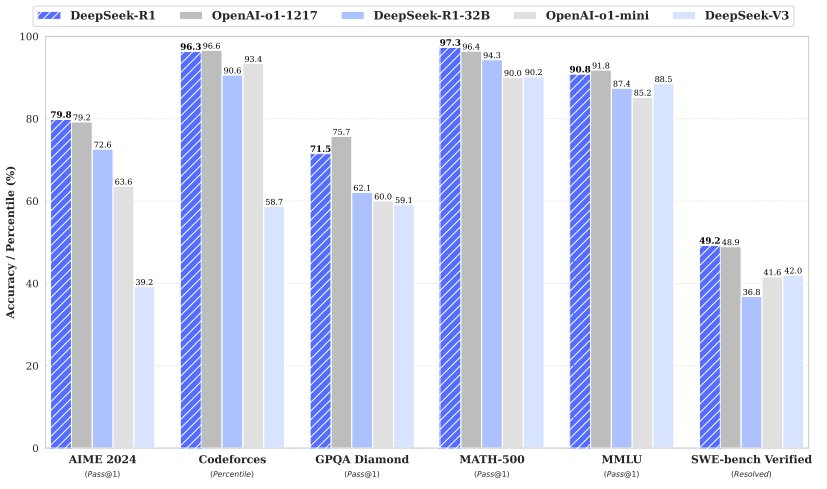
传统的大规模语言模型(LLM)在数学计算方面表现不佳,尤其是面对简单的多位数乘法时,常常出现错误。然而,随着推理模型如o1、o3和DeepSeek-R1的推出,情况正在逐渐改善。例如,DeepSeek-R1在AIME 2024竞赛中取得了79.8%的准确率,而OpenAI发布的o3-mini (high)更是达到了87.3%的准确度。尽管如此,这些模型在处理多位数乘法时仍然存在显著的局限性。
实验结果:多位数乘法的挑战
滑铁卢大学助理教授邓云天通过实验发现,即使是较为先进的模型如o1,在处理超过9×9的乘法时,准确度明显下降。GPT-4o则在4×4乘法时就遇到了困难。最近,邓云天又测试了o3-mini在多位数乘法上的表现,虽然有所进步,但在位数超过13位时,准确度依然大幅下滑。
DeepSeek-R1的表现
机器之心团队也对DeepSeek-R1进行了测试。在尝试两个9位数相乘时,DeepSeek-R1花费了240秒才给出正确答案。而在尝试两个15位数相乘时,虽然用时较短(114秒),但结果却是错误的。这表明即使是最先进的大模型在处理复杂乘法时仍面临挑战。
解决方案:递归式自我提升
微软研究院的研究科学家Dimitris Papailiopoulos及其团队提出了一种基于“递归式自我提升”的方法,可以有效解决Transformer模型在长度泛化方面的局限性。这一方法通过让模型迭代生成自己的训练数据,并逐步学习更复杂的任务,从而实现从简单到复杂的泛化。具体来说,该方法利用了模型的“超越性”,即在简单实例上训练的模型有时能够为更难的实例生成正确的输出。
自我提升框架的应用
研究团队展示了如何通过控制难度调度计划来避免灾难性失败,并通过多数投票和长度过滤等技术保持数据质量。实验结果显示,经过多轮提升后,模型在9位数以内的乘法上几乎达到了完美表现。此外,使用精心设计的调度方案,模型在10位数以内的乘法上也能迅速达到高准确度。
总结与展望
虽然当前的大模型在处理多位数乘法时仍存在局限,但通过递归式自我提升的方法,未来有望大幅提升其在复杂算术任务中的表现。同时,研究者们也在探索如何让大模型直接调用计算器应用,以提高实际应用中的效率和准确性。
 机器之心【阅读原文】
机器之心【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号