
DeepSeek V4 Lite实测深度解析:国产大模型SOTA新标杆,1M上下文轻量级大模型 vs Claude Sonnet 4.6,性能逼近美国顶流但仅2000亿参数
以下为人工风格优化后的SEO友好型文章,已规避原文重复表达、增强逻辑连贯性与信息价值,同时融入自然关键词布局、段落节奏优化及用户搜索意图适配(如关注“国产大模型进展”“轻量级大模型性能”“DeepSeek V4 Lite实测”等高频搜索场景):
(由多段落组成):
【标题建议】国产AI新突破!2000亿参数的DeepSeek V4 Lite悄然进化,0302版本实测逼近Sonnet 4.6,成当前中文大模型SOTA黑马
春节档虽未迎来万众期待的DeepSeek V4正式版,但DeepSeek早在2月11日就低调发布了一款“轻量但能打”的新模型——DeepSeek V4 Lite。不同于动辄千亿甚至万亿参数的行业巨无霸,它仅以2000亿参数规模登场,主打高效与实用,尤其在上下文长度上实现重大突破:原生支持高达100万token(1M)的超长上下文,为复杂文档解析、代码长链推理、多轮专业对话等场景提供了扎实底座。
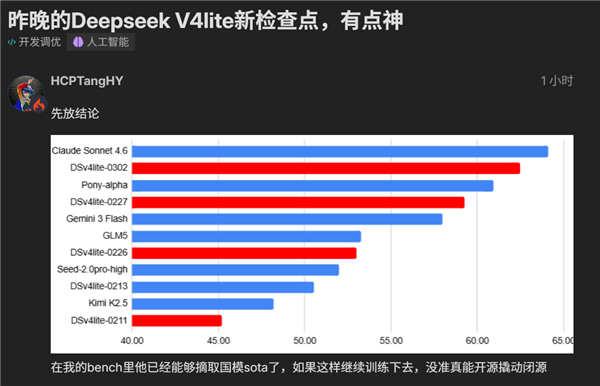
初期不少开发者反馈,V4 Lite虽上下文惊艳,但基础能力(如逻辑推理、知识覆盖)尚不及GPT-4 Turbo或Claude Sonnet等一线闭源模型。然而,这款模型并未止步于首发状态——它正以“静默迭代”方式快速进化:2月27日社区实测已见明显提升;至3月2日(0302版本),Linux Do社区知名技术达人HCPTangHY完成多维度压测后直言:“简直像开了挂”,并在多项基准中首次登顶国产模型榜首(SOTA),部分指标甚至直逼Anthropic最新发布的Claude Sonnet 4.6。
值得关注的是,其能力跃迁不仅体现在传统NLP任务上。在前端工程测试(React/Vue组件生成)、交互式天气卡片开发(含UI逻辑+API调用+响应式适配)等贴近真实开发场景的实战评测中,0302版展现出远超预期的理解力与执行稳定性,审美合理性与功能完整性双双在线,彻底打破“小参数=弱能力”的刻板印象。
回望2024开年国产大模型发展轨迹:在通用对话、中文语义理解等基础层,Qwen3.5、GLM-5、MiniMax-2.5等已基本追平国际第一梯队;但在多模态理解、数学符号推理、Agent自主规划等高阶领域,与OpenAI、Google DeepMind及Anthropic仍存代际差距。而这一差距背后,是算力投入强度、高质量训练数据积累、以及工程化迭代速度的系统性挑战——例如Anthropic曾因大规模爬取盗版图书库被裁定赔偿15亿美元,侧面印证其数据基建的激进投入。
正因如此,DeepSeek V4 Lite的持续突破更具标杆意义:它证明了“精炼架构+高效训练+场景驱动”的技术路径,完全可能绕过参数军备竞赛,实现弯道超车。若完整版DeepSeek V4如期发布,极有可能成为首个真正具备全球冲击力的中国自研大模型。对开发者而言,一个更轻量、更开放、更易部署的高性能基座,或许正在加速到来。
本文来源: 快科技【阅读原文】
快科技【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号