
(由多段落组成):
2025年12月初,国内AI视频生成领域的领军者——可灵AI掀起了一场“技术风暴”。在短短五天内连续发布五项重磅更新,以“狂飙式”节奏完成年末技术冲刺,不仅刷新了行业对生成式AI迭代速度的认知,更将AI创作的边界推向全新高度。这场密集升级背后,是可灵AI在多模态理解、音画协同与创作闭环上的全面突破。
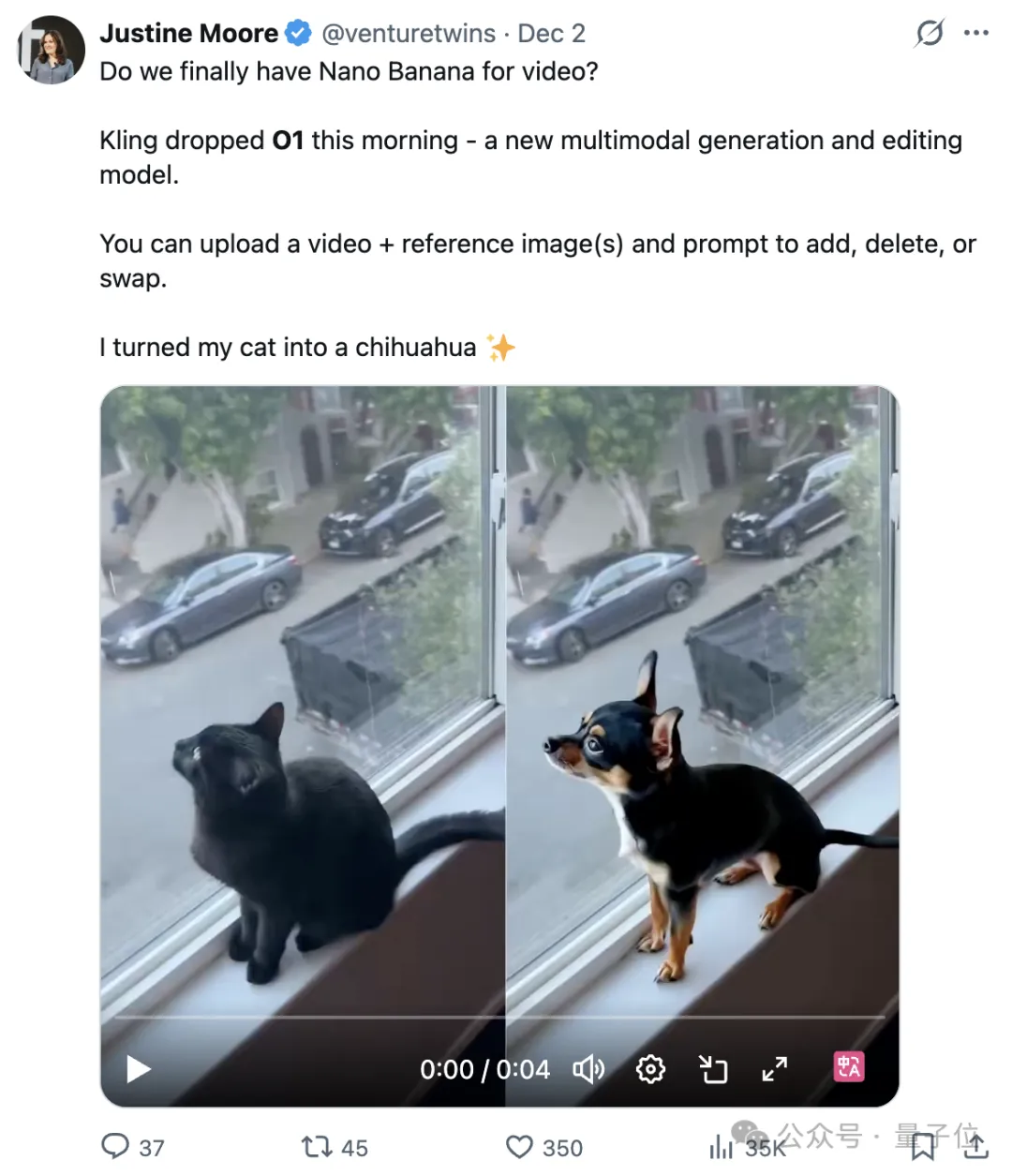
此次最引人注目的创新之一,是全球首个统一多模态创作引擎“可灵O1”的正式亮相。该系统首次将图像生成、视频生成、参考生图、镜头延展、风格迁移、编辑等多种任务整合于同一AI底座之中,真正实现从灵感输入到成品输出的一站式创作流程。基于其独创的Multimodal Visual Language(MVL)交互架构,用户可通过文字、图片、视频片段等多模态提示,精准传达角色身份、动作表情、场景运镜等复杂创意,极大提升了AI生成的可控性与一致性。
尤其在解决长期困扰创作者的“主体一致性”难题上,可灵O1展现出领先优势。无论是通过首尾帧控制视频走向,还是对已有视频进行局部修改和风格重绘,都能在不切换模型的前提下高效完成。据内部测试数据显示,在“图片参考生成”任务中,可灵AI相较Google Veo 3.1的整体表现胜率高达247%;而在指令遵循能力上,对比Runway Aleph也达到230%的领先水平,显示出强大的语义理解与执行能力。
与此同时,可灵2.6模型带来的“音画同出”功能堪称里程碑式进化。过去AI生成视频往往需要“先做画面,再配声音”,流程割裂且耗时费力。而可灵2.6首次实现文本或图文输入后,单次生成即包含自然语音、动作音效与环境氛围音的完整视听,彻底重构了AI视频工作流。目前支持中英文语音生成,视频时长可达10秒,适用于旁白解说、角色对话、Rap说唱、背景音乐等多种音频类型,未来还将拓展更多语言选项与固定声线定制功能。
值得一提的是,这一能力已在全球创作者圈层引发热烈反响。AI电影导演Simon Meyer利用该技术制作的宣传短片,充分展现了音画同步的沉浸感与叙事张力。对于广大自媒体、广告、影视从业者而言,“音画同出”意味着生产效率的指数级提升,也为短视频、电商带货、数字人直播等高频应用场景提供了强有力的技术支撑。
除了核心模型升级,可灵AI还同步推出数字人2.0、主体库管理、对比模板等功能模块,进一步优化实际创作体验。其中数字人2.0允许用户上传角色图像并结合配音与行为描述,快速生成最高达5分钟的高表现力自定义数字人视频,广泛应用于品牌代言、教学讲解、虚拟主播等场景。
截至目前,可灵AI已服务超过2万家企业客户,覆盖影视制作、广告创意、游戏开发、电商平台、自媒体运营等多个领域。快手高级副总裁、可灵AI事业部负责人盖坤多次强调:“我们的目标是让每个人都能用AI讲好一个故事。”从年初的技术探索到年末的批量落地,可灵AI正一步步将这一愿景变为现实。
随着MVL架构的深化、多模态长上下文的理解增强以及物理世界声画语义对齐能力的提升,可灵AI不仅在国内市场持续领跑,也在国际舞台上赢得越来越多的认可。从“威尔·史密斯吃面”这类经典案例的广泛传播,到海外顶尖创作者主动背书,无不印证其技术实力与生态影响力的双重跃迁。可以预见,随着更多行业应用的深入融合,AI原生时代的大门正在加速开启。
可灵AI, 音画同出, 多模态AI, 数字人2.0, 视频生成大模型
本文来源: 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号