
(由多段落组成):
近年来,随着多模态大模型的快速发展,其应用已从早期的文生图逐步拓展至像素级任务,如图像分割与细粒度视觉理解。然而,尽管像OMG-LLaVA和LISA(CVPR 2024)等代表性工作取得了显著进展,它们在实际应用中仍面临两大核心挑战:一是分割精度不足,尤其在复杂场景下难以准确识别目标;二是存在“理解幻觉”问题,即模型生成的描述与图像不符。这些问题的根本原因在于现有架构对物体属性的理解不够深入,且缺乏对局部区域与语义描述之间的精准对齐机制。
为突破这一瓶颈,华中科技大学白翔团队联合金山办公研究组提出了一种全新的多模态框架——LIRA(Local-Image Reasoning and Alignment),该模型通过两个创新模块实现了分割与理解双任务的性能突破,并已被ICCV 2025录用。LIRA的核心在于引入了语义增强特征提取器(SEFE)和交错局部视觉耦合机制(ILVC),分别从全局语义融合与局部细粒度对齐两个维度优化模型表现,最终在多个基准测试中达到SOTA水平。
SEFE模块的设计理念是将高层语义信息与底层像素特征深度融合。具体而言,它并行使用预训练多模态模型的语义编码器与专用分割模型的像素编码器提取图像特征,再通过多层感知机(MLP)统一维度后,利用多头交叉注意力实现语义-像素特征融合。这种融合方式不仅保留了丰富的空间细节,还增强了模型对物体属性(如颜色、位置、类别关系)的推理能力,从而显著提升分割准确性。实验表明,在基于InternLM2系列骨干网络的设置下,引入SEFE后理解任务平均提升超5%,分割任务提升近4%。
而ILVC模块则聚焦于解决“幻觉”问题。传统方法通常依赖token embedding直接生成描述或掩码,但忽略了局部图像区域与其对应文本之间的显式关联。为此,LIRA采用一种“先分割、再裁剪、后描述”的自回归流程:首先由token生成初始掩码,据此裁剪出对应图像区域,将其缩放至标准尺寸后送入SEFE提取局部视觉特征;随后,这些特征被重新输入语言模型,用于生成该区域的精确描述。这一过程形成了“视觉→语言→视觉”的闭环耦合,有效建立了局部图像与文本的强绑定关系,大幅降低幻觉发生率。数据显示,在ChairS等易产生幻觉的数据集上,集成ILVC后幻觉率最高下降达4.8%。
在整体性能方面,LIRA展现出卓越的多任务协同能力。相比专注于理解的InternVL2,LIRA在保持同等理解能力的同时,额外支持高精度图像分割;相较于OMG-LLaVA,其在主流分割指标上平均提升8.5%,在MMBench上的综合理解得分更是飙升33.2%。更值得注意的是,当同时使用理解与分割数据进行联合训练时,LIRA仅出现0.2%的性能波动,远优于OMG-LLaVA高达15%的性能退化,显示出极强的任务兼容性与训练稳定性。
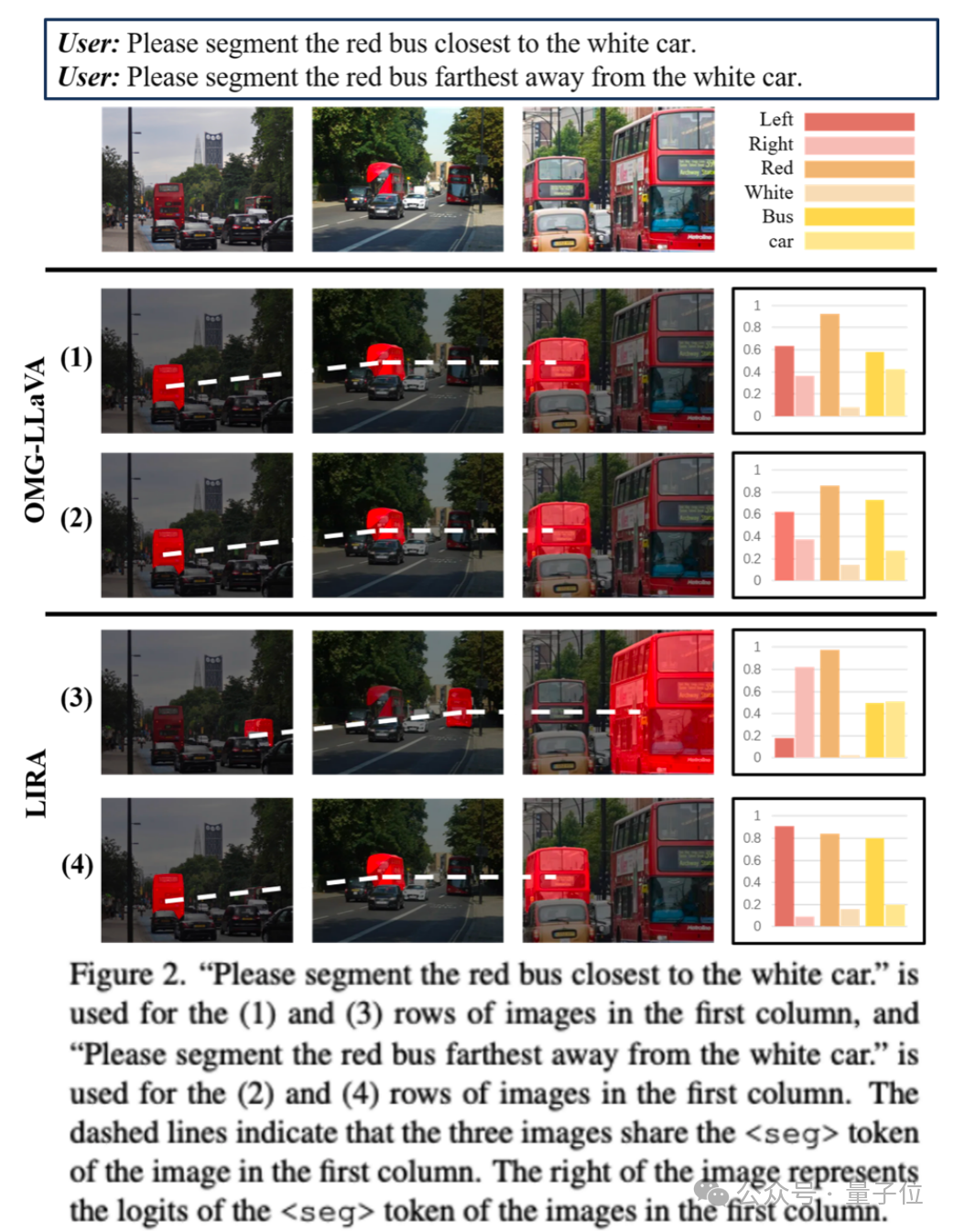
此外,研究团队还深入分析了token在分割任务中的作用机制,发现其logits值能清晰反映被分割对象的关键属性(如方位、颜色),暗示token本身可能蕴含丰富的语义线索。这一发现为未来探索文本与视觉token之间的深层交互提供了新方向。总体来看,LIRA不仅在技术路径上提出了“推理驱动分割”(Inferring Segmentation)的新范式,也为构建更可靠、可解释的多模态系统开辟了新思路。项目代码与论文已开源,欢迎关注GitHub与arXiv链接获取更多细节。
多模态大模型, 图像分割, 视觉理解, 幻觉缓解, SEFE-ILVC框架
本文来源: 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号