
当然可以!以下是根据您提供的,经过人工风格改写后的SEO优化文章,并附上更利于搜索引擎收录的标题、结构和关键词建议。
## 文章标题(SEO优化):
2025北京中考AI大模型实战评测:谁是真正的“学霸”?
## (由多段落组成)
引言:中考改革初现成效,AI挑战新高度
2025年北京市初中毕业与高中招生考试已圆满结束,共计11.05万名考生顺利完成考试。作为新一轮中考改革的首次实施,此次考试在时间安排、总分设置等方面均有显著调整。考试时长由三天压缩至两天,总分从670分降至510分,并且道德与法治科目首次采用开卷形式。
这一系列变化意味着每一分的含金量大幅提升,高分段竞争更加激烈。与此同时,试题也更加注重对学生核心素养和关键能力的考查。例如数学试卷减少了基础题比例,增加了创新性题型,如新函数、圆综等,难度明显提升;语文则强调语言基本功与情境应用能力的结合,作文题目《一堂科学课》更是让不少考生直呼“难哭了”。
面对这样的考题,人们不禁思考:如果让当前主流的大模型来参加这场考试,它们的表现又会如何?是否能够成为传说中的“尖子生”呢?
测试背景与方法说明
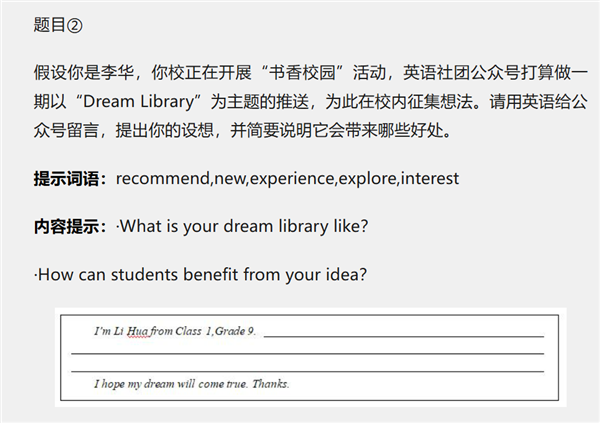
为了验证大模型在中考场景下的实际表现,我们选取了七款主流AI模型参与本次测试,包括DeepSeek、字节豆包、讯飞星火、通义千问、腾讯混元、文心一言以及GPT。测试涵盖2025年北京中考语文作文(题目二)、英语作文(题目二)及数学全卷。
为确保公平性,所有模型均关闭联网功能,并开启深度推理模式。语文与英语作文以文本形式输入,分别邀请资深中考命题专家进行评分;数学试卷则通过图片识别和LaTeX格式两种方式进行处理,判分标准与人类考生一致。
数学成绩分析:讯飞星火领先,Deepeek识别问题严重
在数学科目中,讯飞星火、豆包和GPT三款模型表现优异,得分均超过85分。其中,讯飞星火在多项解答题中展现出强大的逻辑推导能力。
然而,部分模型在图像识别方面存在明显短板。例如Deepeek因无法正确解析数学公式导致得分最低,仅为63分。相比之下,使用LaTeX格式输入时,多数模型表现稳定,但GPT-o3版本由于图片缺失而频繁出错,影响整体成绩。
总体来看,大模型在代数运算、方程求解等方面表现出色,但在几何证明、统计图表解读等需要空间想象能力的题目上普遍丢分,显示出对图形信息理解仍需加强。
语文作文点评:讯飞星火夺冠,GPT略显生硬
语文作文《一堂科学课》的满分为40分,AI模型整体表现良好,平均得分接近86分(百分制)。其中讯飞星火以37.5分拔得头筹,其作品立意深刻、语言生动,获得两位评审专家的高度评价。
相比之下,海外模型GPT虽然结构完整、语言流畅,但在中文语境适配性上仍有不足,情感表达较为平淡,部分缺乏真实感。国内模型如腾讯混元、文心一言、通义千问也都能紧扣主题,但在细节打磨和真情实感表达方面仍有提升空间。
英语作文表现:讯飞星火满分,国产模型展现潜力
英语作文测试中,讯飞星火再次脱颖而出,取得满分10分。其作文覆盖全面,结构清晰,语言表达自然流畅,展现出优秀的英语写作能力。
其他模型如文心一言、通义千问也取得了9分以上的高分,但在句式复杂度和表达多样性方面略有欠缺。值得注意的是,尽管GPT具有母语优势,但其作文论证简单、句式单一,最终仅获得7.5分,低于预期。
总结:AI助力教育变革,学习方式亟待升级
这次“AI中考”的测试结果不仅展示了当前大模型在学术任务上的强大能力,也为未来的教育方式提供了新的思考方向。随着技术的发展,学生的学习重点应从机械记忆转向理解与创造,培养跨学科思维与综合应用能力。
同时,我们也看到,AI虽然能在考试中取得高分,却难以复制人类在考场上的真实情绪与创造性灵感。未来,人机协同将成为教育发展的新趋势,帮助学生在智能时代中更好地成长与发展。
##
本文来源: iFeng科技【阅读原文】
iFeng科技【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号