
字节跳动旗下的Seed项目近期首次开源了其代码模型——Seed-Coder,这款8B参数规模的模型在多个基准测试中取得了SOTA(State of the Art)的表现。Seed-Coder不仅超越了Qwen3等现有模型,还提出了一种创新的数据管理范式,即通过小模型自主生成和筛选高质量训练数据,从而大幅提升代码生成能力。
模型版本与特性
Seed-Coder提供了三个主要版本:Base、Instruct和Reasoning。其中,Instruct版本在编程任务上表现出色,拿下了两个测试基准的SOTA;而推理版本则在IOI 2024比赛中超越了QwQ-32B和DeepSeek-R1。该模型拥有32K上下文长度,使用6T tokens进行训练,并采用了MIT开源协议,完整代码已发布至Hugging Face平台。
数据处理方式
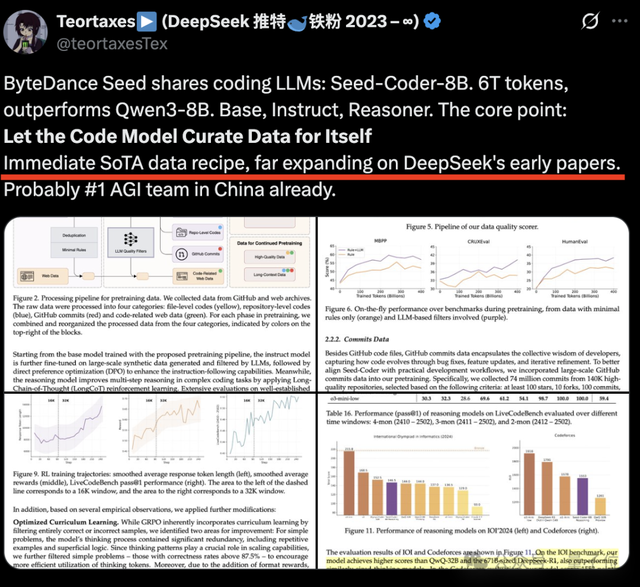
Seed-Coder的核心优势之一在于其独特的“模型中心”数据处理方法。它通过从GitHub和网络档案中爬取原始代码数据,经过多步处理后生成最终的预训练数据集。具体而言,Seed团队将数据分为四个类别:
1. 文件级代码:来自GitHub的单个代码文件,经过处理后保留高质量。
2. 仓库级代码:基于仓库结构的代码文件,帮助模型学习代码间的关联性。
3. Commit数据:包含提交信息、元数据及相关代码补丁,涵盖了14万个高质量仓库的7400万次提交记录。
4. 代码相关网络数据:从网络存档中提取的包含代码块或高度相关的文档。
在数据处理过程中,Seed-Coder采用了双层去重策略(SHA256哈希精确去重与MinHash近似去重),并通过语法解析器剔除低质量文件。此外,团队还开发了一个评分模型,用于过滤低质量代码文件。该评分模型基于DeepSeek-V2-Chat,评估指标包括可读性、模块性、清晰度和可重用性。
预训练阶段
Seed-Coder的预训练分为两个阶段:
– 第一阶段使用文件级代码和代码相关网络数据构建基础能力。
– 第二阶段引入所有四个类别的数据,进一步提升性能并增强对长上下文的理解能力。
为了优化模型表现,Seed-Coder还引入了Fill-in-the-Middle(FIM)和Suffix-Prefix-Middle(SPM)训练目标,分别增强上下文感知完成和中间生成能力。
特殊变体
基于基础模型,Seed团队开发了两个特殊变体:
– 指令模型(-Instruct):通过监督微调(SFT)和直接偏好优化(DPO)提升指令遵循能力。
– 推理模型(-Reasoning):采用LongCoT强化学习训练,提升复杂编程任务中的多步推理能力。
其他进展
除了Seed-Coder外,字节Seed近期还在多个领域取得突破:
– 视频生成模型Seaweed:支持1280×720分辨率视频生成,效果优于更大参数量的模型。
– 深度思考模型Seed-Thinking-v1.5:在数学和代码推理任务中超越DeepSeek-R1。
– 电脑操作智能体UI-TARS:与清华大学合作推出,免费商用,兼容多种系统。
– Multi-SWE-bench:涵盖7种编程语言的多语言基准,包含1632个高质量实例。
字节Seed内部也在持续调整,LLM下的三个团队(Pre-train、Post-train和Horizon)如今直接向负责人吴永辉汇报。同时,代号为“Seed Edge”的研究项目正式启动,专注于AGI前沿研究,探索更长期的基础技术。
本文来源: 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号